Map Reduce 的意义
集群
在传统的单节点模型中,CPU从内存读取数据,当内存空间不够时,再从磁盘读取数据,当磁盘空间不够了呢?
即使磁盘空间足够,磁盘带宽是50MB/sec,若从磁盘读取200TB数据,大约需要46+天,完全没法接受呀!
需要这样一个集群……
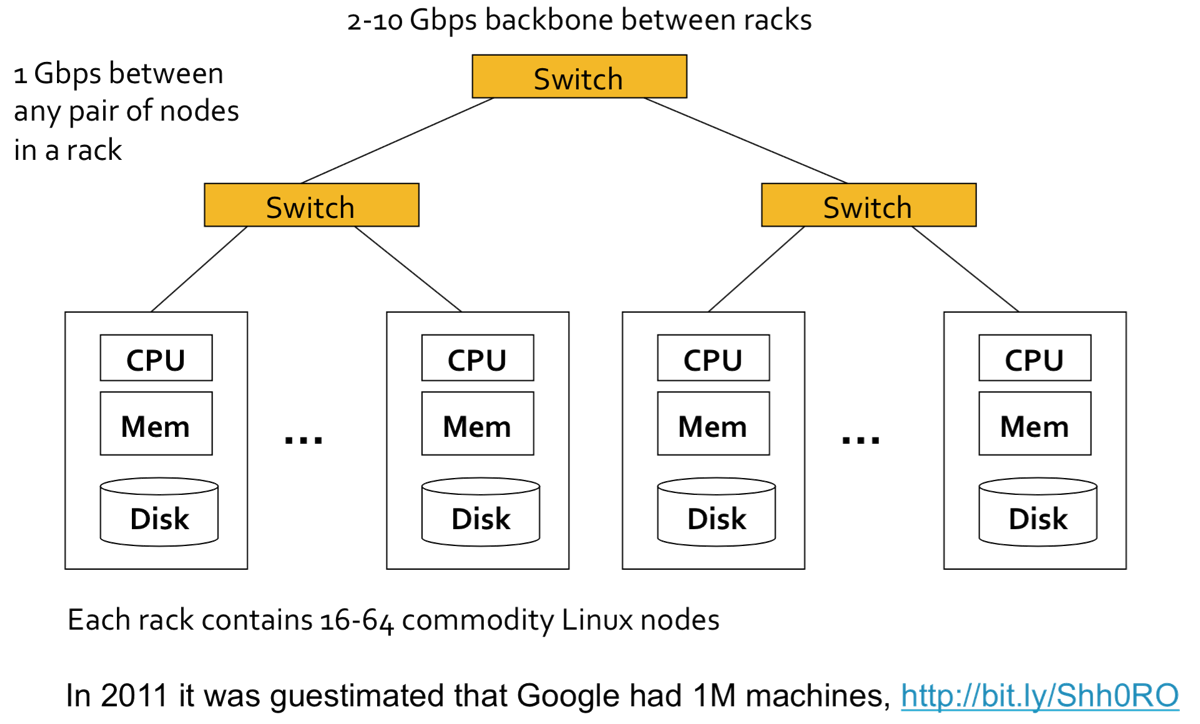
优点(解决困难)
节点故障(node failures)
如果单个服务器能坚持3年(1000天),1000台服务器的集群平均每天大概发生1次故障,1M台服务器的集群平均每天大概发生1000次故障。节点故障时亟须解决的问题:
- 如何存储数据,即使节点故障时仍可用?
- 若正在进行大规模计算,如果节点发生故障该如何处理?
Map Reduce在多个节点冗余存储,保证数据持久存储和获取。
网络瓶颈(network bottleneck)
Map Reduce的计算靠近数据端,减少数据移动。
分布式程序编写困难
Map Reduce简单的编程模型,隐藏了复杂的细节。
Map Reduce 简介
冗余存储架构
冗余存储架构采用分布式文件系统(distributed file system),例如:Google GFS、Hadoop HDFS。典型的应用是处理大文件,一次存储多次读取追加更新。

数据分块(chuck)存储在多台服务器。如上图所示,一个大文件分割成C0~C5共6块,每块在多台服务器存储备份。每台存储服务器也做计算用,使得计算靠近存储端。
计算模型
1 |
输入:key-value对的集合 |
Map-Reduce的计算模型分为Map和Reduce两步,Map分布式处理任务,Reduce合并任务。
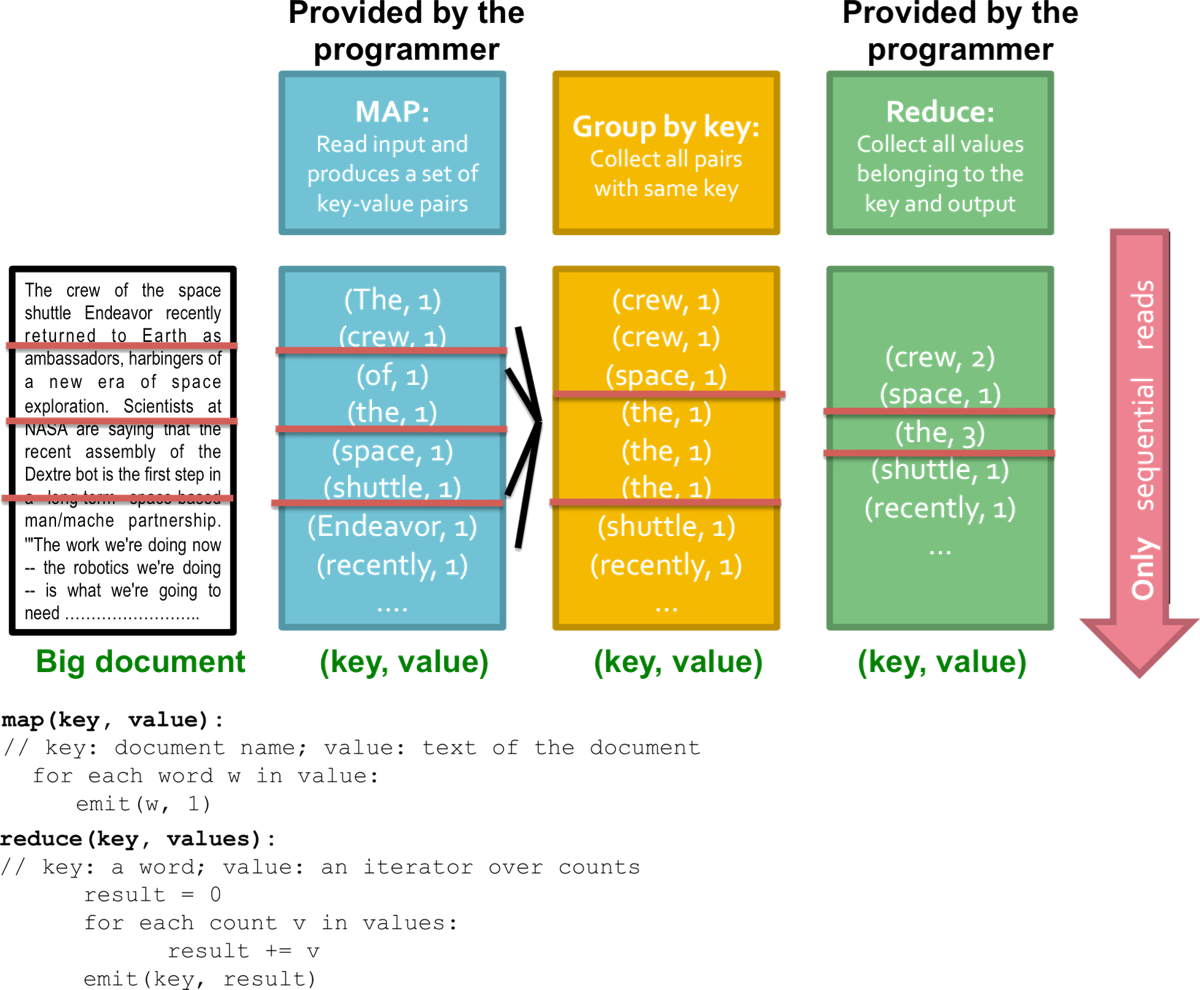
上图展示了用Map-Reduce统计超大规模文件中单词出现次数,红色横线将不同节点的实现分割开。对于Map节点,所有相同单词都输出到同一个节点,比如the都在第二个节点。为了保证效率,Map-Reduce都采用的是顺序读取。
调度与数据流
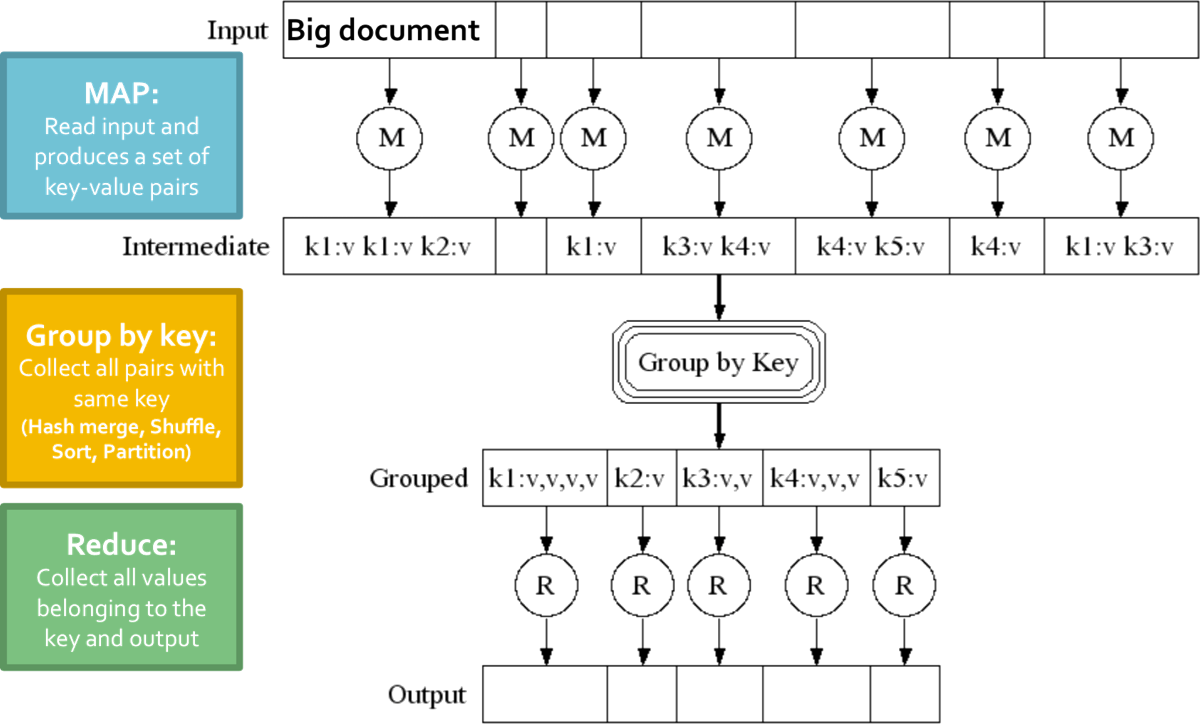
Map-Reduce的数据流:
- 输入输出存储在分布式文件系统;
- 中间结果存储在本地文件系统;
- 输出通常再输入到另一个Map-Reduce任务。
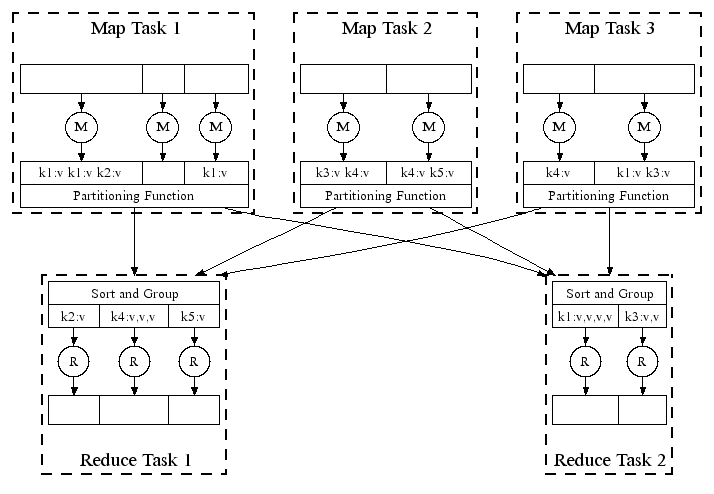
上图是Map-Reduce分布式系统的并行实现,Partition Function部分采用Hash算法,将相同key的value映射到同一节点。
Map-Reduce环境的主要任务:
- 分割输入数据;
- 多机之间程序调度;
- 执行按key分组操作;
- 处理节点故障;
- 处理多机间通信。
Map Reduce的实现分为Master节点、Map节点和Reduce节点,Master节点的任务:
- 管理每个任务状态:空闲(idle,等待处理)、处理中(in-progress)、completed(结束);
- 将空闲任务安排到可用节点;
- 当Map任务结束,向Master发送其R中间文件(存放在本地文件系统中)的位置和大小,每个reducer一个中间文件;
- Master推送信息到Reducer;
- Master周期性ping检测节点是否出故障。
Map Reduce系统有M个Map任务和R个Reduce任务,M比集群中的节点数目大得多,R通常比M小。
Map Reduce 的改进
合并操作
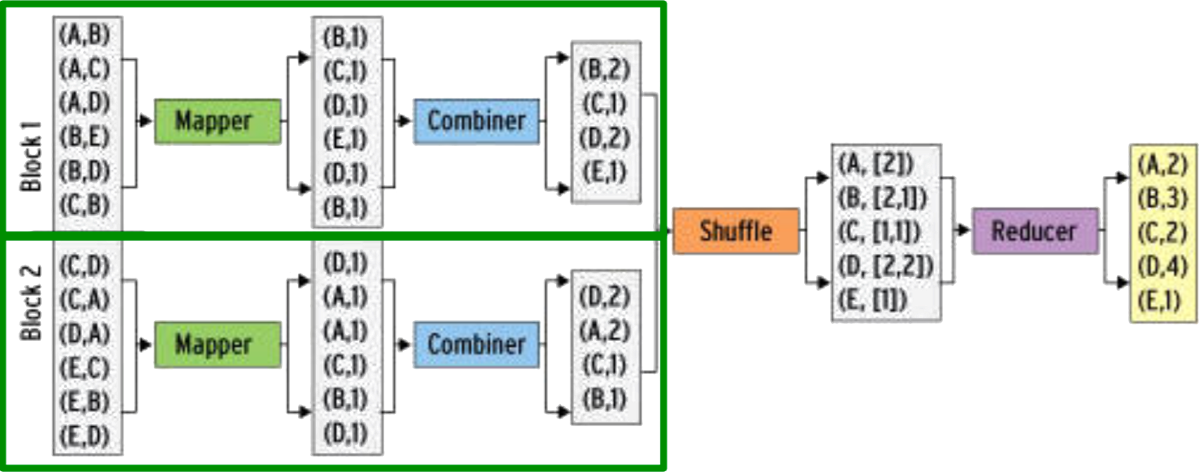
通常在一个Map任务中会产生多个相同key的(k,v)对,在Map节点合并这些相同的key可有效降低网络流量,如上图所示。合并函数通常与Reduce函数相同。
合并时需要注意Reduce函数是否支持在Map节点的合并操作,也就是合并操作会不会改变Reduce的结果。
改写分割函数
例如:系统采用的默认分割函数hash(key) mod R可以改写为hash(hostname(URL)) mod R,使同一个主机的url输出到相同的文件。
The link of this page is https://blog.nooa.tech/articles/25d9ef10/ . Welcome to reproduce it!