页框管理与伙伴系统
这里的内存管理,指的是内核如何分配(为自己)动态内存。linux把页框作为一个管理的基本单位,用数据结构page对其进行描述。而所有的page则放在一个mem_map数组当中,进行管理。但计算机存在着一些限制,因此linux把内存划分为了几个管理区,包括ZONE_DMA、ZONE_NORMAL、ZONE_HIGHMEM等;而对页框的分配和释放,也是按照分区来进行管理的:
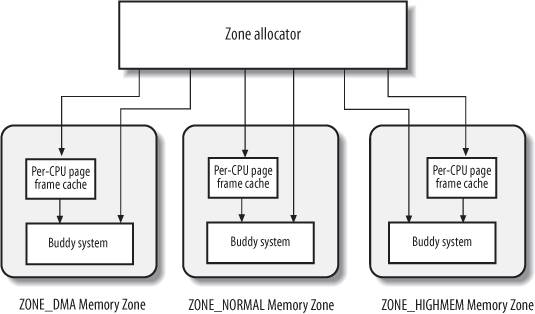
在每个分区之内,页框由伙伴系统来进行处理。伙伴系统主要是为了解决“外碎片”的问题:当请求和释放不断发生的时候,就很有可能导致操作系统中发生存在空闲的小块页框,但是没有大块连续页框的问题。伙伴系统把空闲页分组成11个块链表,分别包含1,2,4,6,…,1024个连续的页框。每当有两个连续的大小为b的页框出现时(并且起始地址满足一个倍数条件),它们就被视为伙伴,伙伴系统就会把它们合并成大小为2b的页框。在页分配时,如果当前大小b的free_list中找不到空闲的页框,就会从2b的链表中寻找空闲页块,并且进行分割,将它分为两个大小为b的页块。
每个伙伴系统,管理的是mem_map的一个子集。在管理区描述符中,有一个struct free_area,它用来辅助伙伴系统:
1 |
struct free_area { |
free_list是用来连接空闲页的链表数组,而nr_free则是当前内存区中空闲页块的个数。
反碎片
当然,上面说到的只是最基本的伙伴系统,但它并没有完全解决碎片的问题。linux中还采用了一种反碎片的机制,它根据已内存页的类型来工作:
- 不可移动页:在内存中有固定的位置,不能移动到其他地方(kernel的大多数内存页)
- 可移动页:用户空间的页,只要更新页表项即可
- 可回收页:在内存缺少时,可以进行回收的页,例如从文件映射的页
(以及一些其他类型)
如果根据页的可移动性,将其进行分组,避免可回收页和不可回收页的交叉组织(例如在可移动页中间有不可移动页),并且在某个类型的页分配失败时,会从备用列表中寻找相应的页,这个顺序定义在page_alloc.c当中。
内存分配方法
分配内存通常可以调用一下几个函数:
- alloc_pages/alloc_page:分配若干个页,返回第一个struct page
- get_zeroed_page:分配一个struct page,并且将内存填0
- get_free_pages/get_free_page:返回值是虚拟地址
- get_dma_pages:分配一个适用于DMA的页
还有一些基于伙伴系统的方法,它们可能会借助页表进行映射,例如vmalloc,kmalloc。
内存分配时,通常要指定一个掩码gfp_mask,它定义了页所位于的区域、页在I/O和vfs上的操作,以及对分配操作的规定(阻塞、I/O、文件系统等)。
释放不再使用的页,同样可以采用struct page或者虚拟地址作为参数:
- free_page/free_pages:以struct page为参数
- __free_page/__free_pages:以虚拟地址为参数
页框高速缓存
(为了避免混淆,我把所有硬件的高速缓存称为cache)
内核经常会请求、释放单个页框,为了提高系统的性能,每个内存管理区都有一个每CPU的页框高速缓存,它包含一些预先分配的页框,能够用来满足CPU发出的单个页框请求。注意,这个页框高速缓存,和硬件上的cache的概念不同,但它们有一点小小的关联。由于每个CPU有自己的cache,那么假设一个进程刚刚释放了一个页,那么这个页就有很大概率还在cache当中。页框高速缓存保存热页(刚释放的,很可能在cache当中的页)和冷页(释放时间比较长的页)。其实对于分配热页来说,很好理解:用在cache中的页可以减少开销;但如果说是DMA设备使用,就要分配冷页了,因为它不会用到cache。
slab分配器
前面所说的伙伴系统,是用“页”为单位来进行,显然太大了;所以需要把页进一步拆分,变成更小的单位。slab分配器不仅仅提供小内存块,它还作为一个缓存使用,主要是针对那些经常分配、释放的对象:例如内核中的fs_struct数据结构,可能经常会分配和释放;那么slab就将释放的内存块保存在一个列表里面,而不是返回给伙伴系统。这样一来,再次分配新的内存块时,就不需要经过伙伴系统了,而且这些内存块还很可能在cache里面。
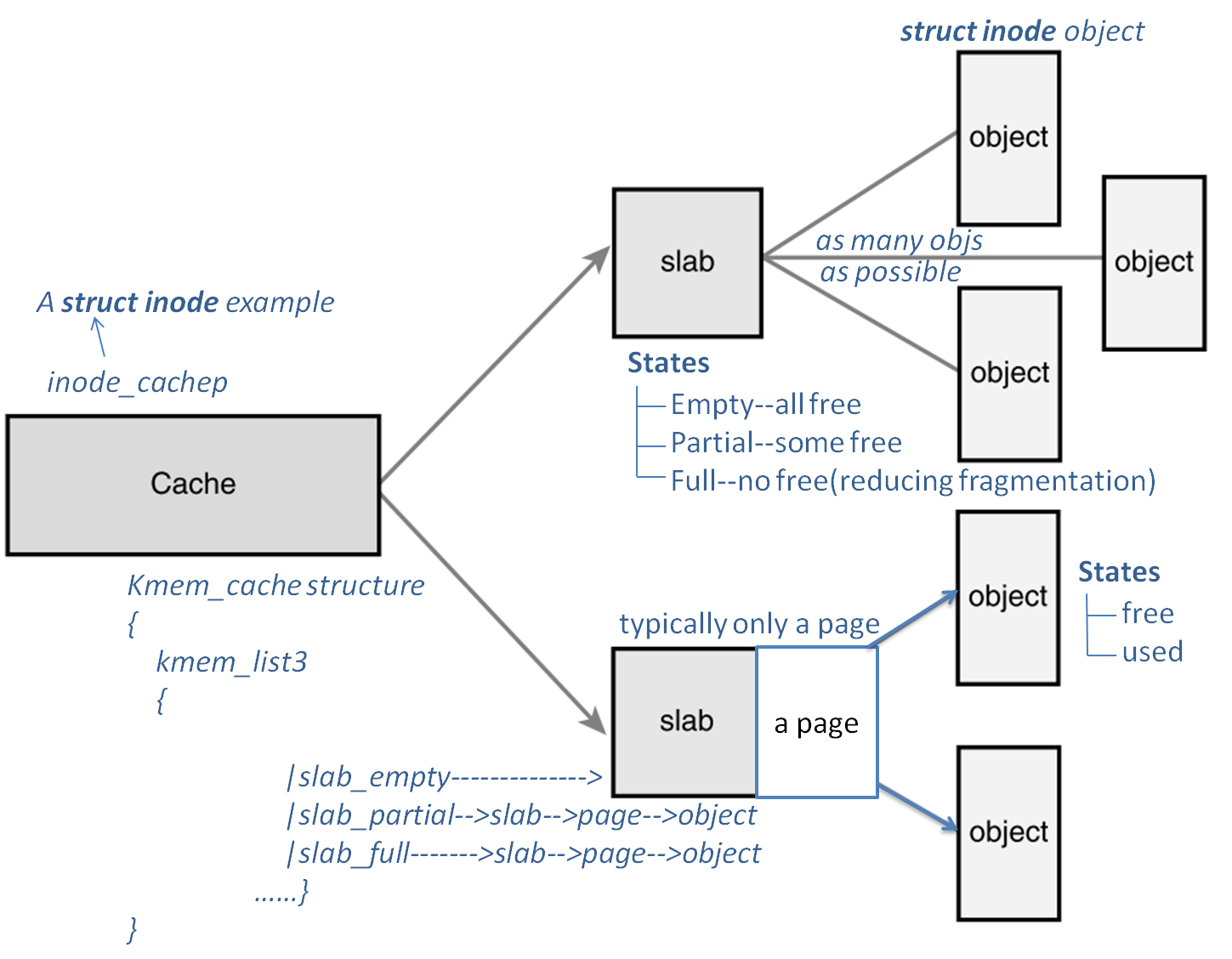
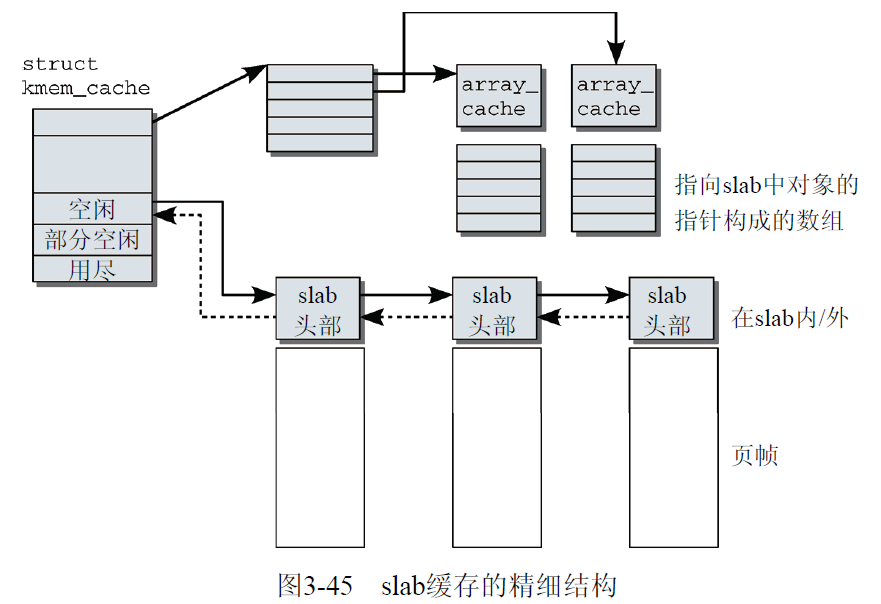
slab分配器包含几个部分:高速缓存kmem_cache,slab,以及slab中所包含的对象。每个高速缓存只负责一种对象类型,它由多个slab构成。kmem_cache当中有三个slab链表,分别对应用尽的slab、部分空闲的slab,和空闲的slab,还有一个array_cache *数组,它保存cpu最后释放的那些很可能处于“热”状态的对象。
而对于每个slab,则组织了一系列的object;它包含了空闲对象,正在使用的对象。那么为什么不直接用kmem_cache管理对象,要增加出slab这一层呢?这明显是为了更好的管理内存:通过slab,可以让内存的使用更平均,或者能够更好的管理空闲的页。
在新版本的内核中,slab由kmem_cache_node来管理,它包含3个链表slabs_partial,slabs_full和slabs_free。每个slab是一个或多个连续页帧的集合,每个objects由链表串联,现在slab中的object直接由page中的freelist来管理了。
1 |
struct kmem_cache_node { |
值得一提的是,kmalloc的实现也是也是基于slab来实现的,它包含一个数组,存放了一些用于不同长度的slab缓存,这也就是我们所说的“内存池”。
slab着色
slab着色与颜色并没有关系,它要解决的问题与硬件高速缓存有关。硬件高速缓存倾向于把大小一样的对象放在高速缓存内的相同偏移位置;而不同slab当中相同偏移量的对象,就会映射在高速缓存的同一行当中;这样高速缓存可能就会频繁的对同一高速缓存行进行更新,从而造成性能损失。
slab着色就是给每个slab分配一个随机的“颜色”,把它作为slab中对象需要移动的特定偏移量来使用,这样对象就会被放置到不同的缓存行。
The link of this page is https://blog.nooa.tech/articles/41e39f2b/ . Welcome to reproduce it!