我们先从分析原理入手,然后再使用Python提供的基本的库urllib。
注意,我全程使用的是Python3,如果你必须使用不同版本,请自行百度某些库及函数的转换,需要使用的库不一定你的电脑上预装了,所以请自行百度安装。
原理
网络爬虫,也叫网络蜘蛛(Web Spider),如果把互联网比喻成一个蜘蛛网,Spider就是一只在网上爬来爬去的蜘蛛。网络爬虫就是根据网页的地址来寻找网页的,也就是URL。
URL
URL就是统一资源定位符(Uniform Resource Locator),它的一般格式如下(带方括号[]的为可选项):
protocol ://hostname[:port]/path/[;parameters][?query]#fragment
可见,一个URL包含三个部分:
- protocol:协议,例如https,http等;
- hostname[:port]:主机名(端口号为可选参数),一般网站默认的端口号为80,例如我的博客域名www.meng.uno,可以作为主机名使用;
- path:第三部分就是主机资源的具体地址,如目录和文件名等。
爬虫就是向URL发送请求,然后得到响应,基本就实现了爬取网页的功能。
URI可以分为URL,URN或同时具备locators 和names特性的一个东西。URN作用就好像一个人的名字,URL就像一个人的地址。换句话说:URN确定了东西的身份,URL提供了找到它的方式。
从浏览器发送和接收数据看起
进入我的首页www.meng.uno,打开浏览器的“检查”功能,选项卡选到“Network”,然后点击所有文章,随便选择一条,我们可以发现如下截图的"Headers"
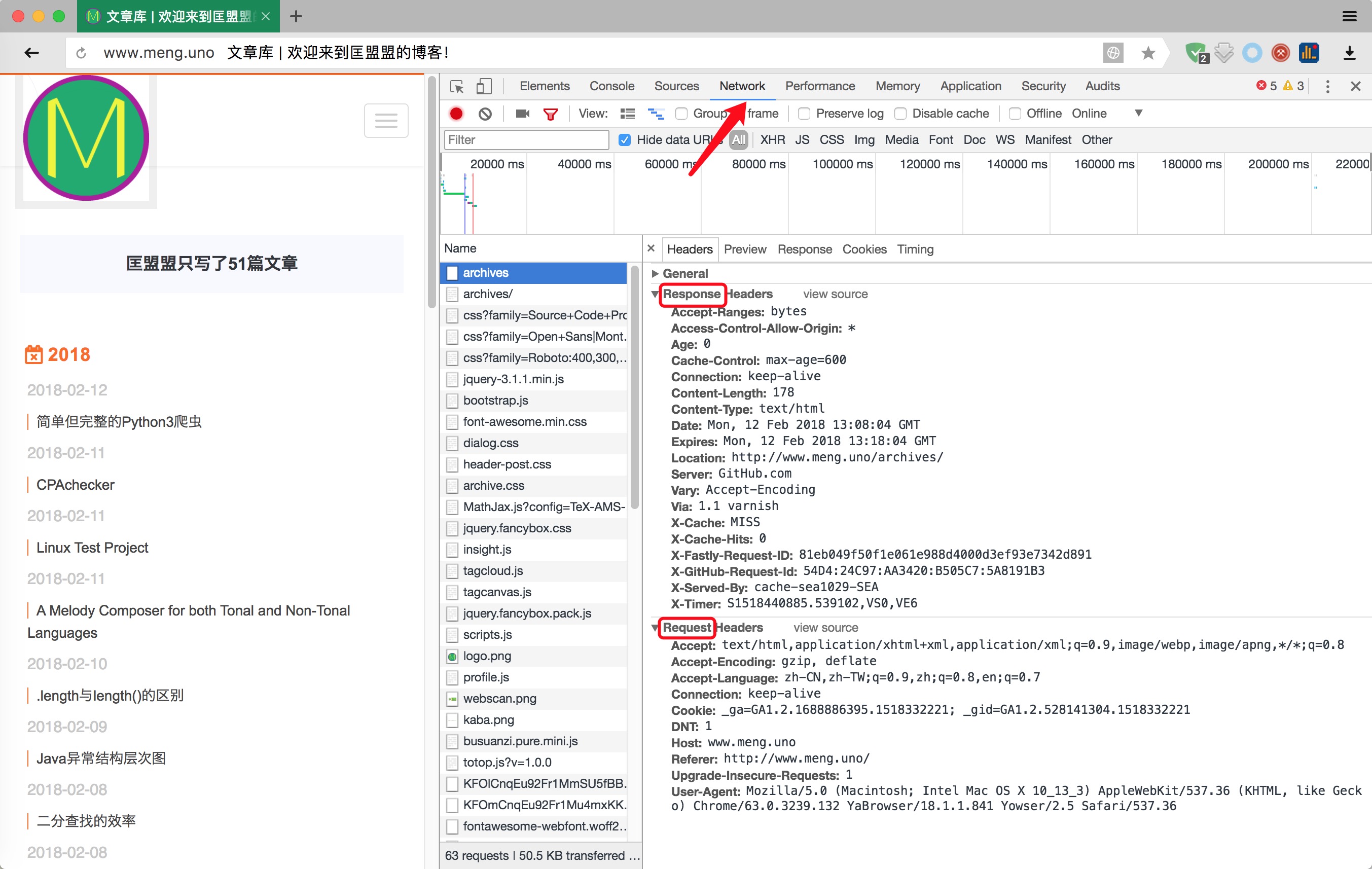
我们可以发现最明显的有两个区域(我已经圈出来了):“request”和“response”。从字面意思上来看,我们就知道分别是(发送的)请求和(收到的)回复。
接收的信息是我们请求的网页给的,不用我们管,但是“请求的网页”是我们需要提前设定的,当然最简单的方式就是什么都不设置。爬虫会增加网站的负荷,所以很多网站希望大家通过API的方式使用其开放的资源而禁止爬虫,其中的一个做法就是判断你的请求内容(不全的基本都是爬虫)。于是,为了做到一个完整的可用的爬虫,我们需要模拟真实用户的请求,这就要求我们伪造“User Agent”。
常见的“User Agent”列举如下:
-
Android
- Mozilla/5.0 (Linux; Android 4.1.1; Nexus 7 Build/JRO03D) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.166 Safari/535.19
- Mozilla/5.0 (Linux; U; Android 4.0.4; en-gb; GT-I9300 Build/IMM76D) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30
- Mozilla/5.0 (Linux; U; Android 2.2; en-gb; GT-P1000 Build/FROYO) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1
-
Firefox
- Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0
- Mozilla/5.0 (Android; Mobile; rv:14.0) Gecko/14.0 Firefox/14.0
-
Google Chrome
- Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36
- Mozilla/5.0 (Linux; Android 4.0.4; Galaxy Nexus Build/IMM76B) AppleWebKit/535.19 (KHTML, like Gecko) Chrome/18.0.1025.133 Mobile Safari/535.19
-
iOS
- Mozilla/5.0 (iPad; CPU OS 5_0 like Mac OS X) AppleWebKit/534.46 (KHTML, like Gecko) Version/5.1 Mobile/9A334 Safari/7534.48.3
- Mozilla/5.0 (iPod; U; CPU like Mac OS X; en) AppleWebKit/420.1 (KHTML, like Gecko) Version/3.0 Mobile/3A101a Safari/419.3
User Agent已经设置好了,但是还应该考虑一个问题,程序的运行速度是很快的,如果我们利用一个爬虫程序在网站爬取东西,一个固定IP的访问频率就会很高,这不符合人为操作的标准,因为人操作不可能在几ms内,进行如此频繁的访问。所以一些网站会设置一个IP访问频率的阈值,如果一个IP访问频率超过这个阈值,说明这个不是人在访问,而是一个爬虫程序。
一个很简单的解决办法就是设置延时,但是这显然不符合爬虫快速爬取信息的目的,所以另一种更好的方法就是使用IP代理。使用代理的步骤:
- 调用urlib.request.ProxyHandler(),proxies参数为一个字典;
- 创建Opener(类似于urlopen,这个代开方式是我们自己定制的);
- 安装Opener;
这个网站提供了很多代理主机:http://www.xicidaili.com/
正则表达式
我直接以表格的形式呈现好了:
| 元字符 | 说明 |
|---|---|
| . | 代表任意字符 |
| [ ] | 匹配内部的任一字符或子表达式 |
| [^] | 对字符集和取非 |
| - | 定义一个区间 |
| \ | 对下一字符取非(通常是普通变特殊,特殊变普通) |
| * | 匹配前面的字符或者子表达式0次或多次 |
| *? | 惰性匹配上一个 |
| + | 匹配前一个字符或子表达式一次或多次 |
| +? | 惰性匹配上一个 |
| ? | 匹配前一个字符或子表达式0次或1次重复 |
| {n} | 匹配前一个字符或子表达式 |
| {m,n} | 匹配前一个字符或子表达式至少m次至多n次 |
| {n,} | 匹配前一个字符或者子表达式至少n次 |
| {n,}? | 前一个的惰性匹配 |
| ^ | 匹配字符串的开头 |
| \A | 匹配字符串开头 |
| $ | 匹配字符串结束 |
| [\b] | 退格字符 |
| \c | 匹配一个控制字符 |
| \d | 匹配任意数字 |
| \D | 匹配数字以外的字符 |
| \t | 匹配制表符 |
| \w | 匹配任意数字字母下划线 |
| \W | 不匹配数字字母下划线 |
代码
简单带错误信息的获取网页内所有URL的爬虫
1 |
#获取URL的包 |
模拟真实环境的爬虫
1 |
import urllib |
通过队列获取网站所有URL的爬虫
1 |
#python系统关于队列的包 |
这里先简单解释,以后有实际项目会再补充!
The link of this page is https://blog.nooa.tech/articles/51d32f19/ . Welcome to reproduce it!