.length与length()的区别
当我们需要使用数组或者字符串长度时,习惯了使用IDE自动补全的我们是否知道
.length与length()的区别喻原因呢?
上面问题的答案是:
- 数组使用
.length属性 - 字符串使用
length()方法
为什么数组有.length属性?
在Java中,数组是容器对象,其中包含了固定数量的同一类型的值,一旦数组创建,其长度就是固定的了,于是,其长度可以作为一个属性。
为什么字符串需要length()方法?
Java中的String,实际上是一个char类型数组,而char[]已经有了.length属性,所以在实现String时就没必要再定义重复的属性了,于是需要定义一个方法来返回其长度。
Substring()的实现
写过Java的人应该都用过substring(int bedinIndex, int endIndex)方法。我发现这个简单的方法在实现上居然经过了一次大的变革。
substring()的用途
代码:
1 |
String origin = "asdfg"; |
输出:
1 |
sd |
我们发现它能将原始字符串中从下标为beginIndex到endIndex-1之间的子串取出。那它是怎么实现的呢?
substring()的实现
Java中的字符串有三个域:char value[], int offset以及int count,它们分别存储字符串的值,起始下标与长度。
JDK6版本
在这个版本中,每次执行substring()方法时并不会新建新的string,仅仅只是将上述三个域中的offset,count做必要的修改。返回对象仍指向原来的数据。
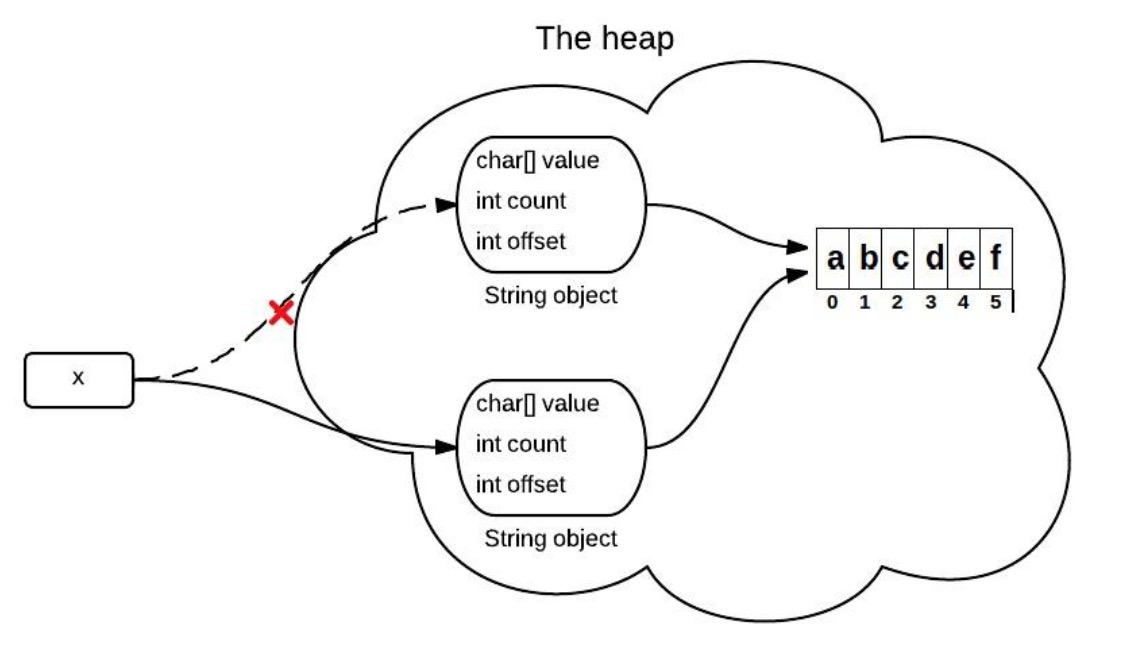
这样一来,缺点就比较明显:当原始字符串比较长,而截取的子串比较短时,在后续的使用中就会浪费大量的空间。
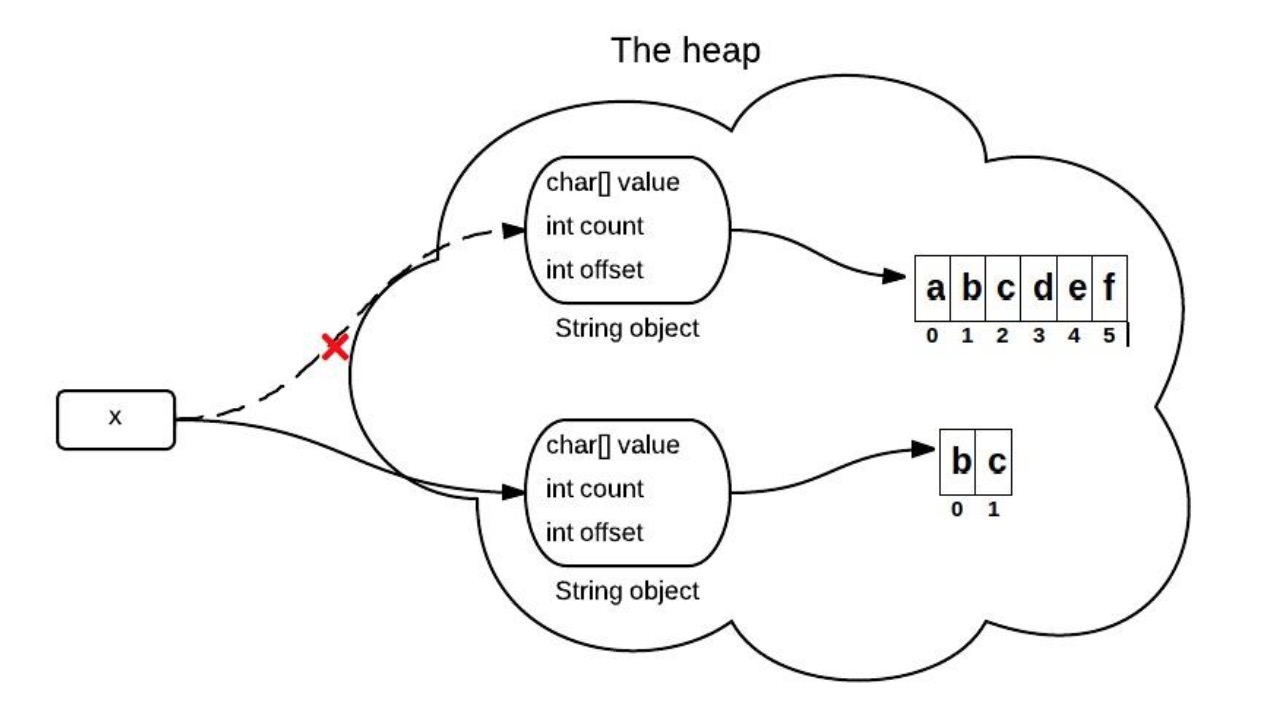
JDK7+版本
在上一个版本基础上,这个方法进行了改进,每次使用这个方法都会新建一个string对象,并将其返回。
String+操作分析
背景
昨天,我和队友讨论字符串拼接问题时,他提到了这个问题:直接“+”操作好像是生成了临时的一个新String,然后拼接,再复制给原来的String。带着这个问题,我查了下,得出以下的结论。
结论
我查到的信息之一这样说:因为“+”拼接字符串,每拼接一次都是再内存重新开辟一个新的内存区域(堆里边),然后把得到的新的字符串存在这块内存,字符串如果很大,循环次多又多,那么浪费了很多时间和空间的开销。
我查到的信息之二这么说:当拼接次数较少时,其实编译器会将其优化为StringBuilder类型,只是当拼接次数特别多时,编译器优化时将会产生过多的StringBuilder类型,从而导致空间浪费。
策略
当拼接次数较少时,我们可以直接使用“+”操作,而当拼接数量较大时,我们最好使用StringBuilder类型。
操作
1 |
StringBuilder SB = new StringBuilder(); |
Java中的Lambda表达式
Java8已经更新了好久了。变化很大,其中最广为人知的就是
Lambda表达式。
Lambda表示式
Lambda的基本格式为()->内容,以箭头为分隔,左边为参数区,右边为代码区。
可以把它看成是一个临时定义的方法,没有方法名,默认为public,根据代码区里的有没有return来决定返回值.如果没有return则是void。
- 单行代码可以省略return
- 多行代码使用
{}来包裹. - 代码内可以引用外部局部变量,实际上是隐式的把变量变成
final
网上用得最多的例子就是(x,y)->x+y;,很蛋疼的例子,当初看Junit单元测试时也是这样的例子。
来个实际点的例子吧:
1 |
public boolean isEmpty(String text){ |
看到这里估计很多人会觉得更蛋疼了。明明Lambda使用是的匿名内部类的简写,为什么要拿方法来做比较,另外明明有方法可以调用,何必要用Lambda。
Lambda的起源
曾经无数次的羡慕js有闭包,可以把方法当做参数来传递。在项目中有很多类都存在着很类似的方法:
1 |
public String getIds(List<T> list){ |
想抽取一下,奈何每个类里T不同,doSomething的实现也不同.T可以用泛型,doSomething(T t)这个方法怎么传呢?
面向接口吧。我们可以定义一个接口来干这个事:
1 |
public interface GetId<T>{ |
上面的方法就可以抽到工具类中了:
1 |
public static <T> String getIds(List<T> list,GetId<T> interf){ |
说来说去好像不关Lambda什么的事呀.实际上上面的例子就是Lambda的起源。
随着函数式编程广为程序员喜爱,Java也在考虑加入函数式编程.但有两个问题,一 做为一个强类型语言,类型转换有点蛋疼,二 不能把方法当成参数(有返回值的还好,void方法当参数是相当的无语的)。
Java考虑了半天,使用了上面的例子的逻辑来处理,用接口来包装方法,把接口当参数来代替。
上面的例子中。在类中调用如下:
1 |
String ids=Utils.getIds(List<XXX> list,new GetId<XXX>(){ |
这是一个参数,如果是多个参数那不要吓死人:
1 |
String ids=Utils.getIds(List<XXX> list, |
所以Lambda第一个作用就体现出来了简化书写,好写好看。如:
1 |
String ids=Utils.getIds(List<XXX> list,(x)->ooxx(x)); |
这里有点奇怪x是什么呢?其实完整的应该是:
1 |
String ids=Utils.getIds(List<XXX> list,(XXX x)->ooxx(x)); |
这里就体现了lambda的牛逼之处类型推导(准确来说是Java8的特性),编译时推导参数类型和返回类型。
最上面那个坑爹的例子估计很多人都会像我当初一样蒙B。(x,y)->x+y;,这x和y是什么的东西?
实际上这个例子应该是(int x,int y)->return x+y;,这样看就清楚多了,传两个int,返回其和。
再给个实际点的例子吧:
1 |
String[] strings={"xx","oo","xxoo"}; |
Lambda的实现
lambda的原理就是以把接口当参数传递的方式来形成闭包.所以这个接口只能定义一个方法,这种接口叫函数接口.这种接口可以隐式转为lambda。
为了防止该接口的单方法性被破坏,Java8定义了一个注解FunctionInterface,Java库中所有这种接口都已经添加了这个注解。如:
1 |
|
当然,自己也可以定义函数接口,很简单,只要是单方法都可以。最好是加上注解,防止自己或别人去添加新的方法。
另外Java8中提供了很多常用的接口,免得自己去创建。这些接口放在java.utils.function包里。
默认的接口可接收和返回的基本数据只有int,long,double三种,String视为对象。
- Custmer一家,提供了
void类的接口,可以接收单个或两个的基本数据类型或对象的参数(无参的有现成的Runable)。如:
1 |
interface Custmer<T>{ |
另外还支持对象+基本数据类型的参数。
-
Predicate一家,提供了可接收1-2个基本数据类型或对象的参数,返回
boolean的接口(无参的是booleanSupplier接口)。 -
Function,Oprator,Supplier一家,提供了接收0-2个参数,返回基本数据类型或对象的接口。
- Function一家可接收1-2个参数,返回的是对象
- Supplier一家不接收参数,返回基本数据类型和对象
- Operator一家接收1-2个参数,返回同类型的数据。
unary前缀的是接收一个参数,binary前缀的是接收两个参数。那个坑爹的(x,y)->x+y的例子就是由IntBinaryOperator接口来实现的。
1 |
interface IntBinaryOperator{ |
默认提供的接口,如果是两个基本数据类型的参数,则参数的类型都必须是相同的.也就是说两个以内的参数基本上不用自己定义函数接口了。上面的例子就可以这样写:
1 |
public static <T> String getIds(List<T> list,Function<T,String> interf){ |
函数式编程
函数式编程需要可以把函数当成参数,在Java中所有的东西都是需要有类型的,只有函数自身是没有的。Lambda以间接的方式提供了函数的类型,及类型的推导,为函数式编程清扫了最大的障碍。再配合新提供的Stream,在Java中终与可以愉快的的使用函数式编程了。
然而,没有Lambda,没有Java8, Rxjava一样可以愉快的函数式编程。
Lambda表达式与匿名类的区别
使用匿名类与 Lambda 表达式的一大区别在于关键词的使用。对于匿名类,关键词this解读为匿名类,而对于 Lambda 表达式,关键词this解读为写就 Lambda 的外部类。
Lambda 表达式与匿名类的另一不同在于两者的编译方法。Java 编译器编译 Lambda 表达式并将他们转化为类里面的私有函数,它使用 Java 7 中新加的invokedynamic指令动态绑定该方法。
The link of this page is https://blog.nooa.tech/articles/61c2f1f1/ . Welcome to reproduce it!