过去很长时间以及现今,电商都在蓬勃发展,支持电商越做越大的一个很重要的因素就是“商品推荐”。当我们打开天猫,我们发现不同的用户,一般而言,首页是不一样的,原因就是,它为不同的用户推荐了不同的商品。我们为什么要用某一个购物网站或者APP,我觉得很大程度上取决于其推荐的准确与否。本篇博客我将向大家介绍协同过滤在商品推荐上的应用。
关于推荐系统
根据推荐引擎的数据源不同,一般而言,推荐系统可以分为如下三类:
- 基于人口统计学的推荐机制(Demographic-based Recommendation):根据系统用户的基本信息发现用户的相关程度。
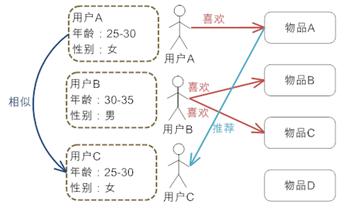
- 基于内容的推荐机制(Content-based Recommendation):根据推荐物品或内容的元数据,发现物品或者内容的相关性。
- 协同过滤的推荐机制(Collaborative Filtering-based Recommendation):根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性。
根据推荐模型的建立方式不同,推荐系统可以分为这样三类:
- 基于物品和用户本身。这种推荐引擎将每个用户和每个物品都当作独立的实体,预测每个用户对于每个物品的喜好程度,这些信息往往是用一个二维矩阵描述的。由于用户感兴趣的物品远远小于总物品的数目,这样的模型导致大量的数据空置,即我们得到的二维矩阵往往是一个很大的稀疏矩阵。同时为了减小计算量,我们可以对物品和用户进行聚类, 然后记录和计算一类用户对一类物品的喜好程度,但这样的模型又会在推荐的准确性上有损失。
- 基于关联规则的推荐(Rule-based Recommendation)。关联规则的挖掘已经是数据挖掘中的一个经典的问题,主要是挖掘一些数据的依赖关系,典型的场景就是“购物篮问题”,通过关联规则的挖掘,我们可以找到哪些物品经常被同时购买,或者用户购买了一些物品后通常会购买哪些其他的物品,当我们挖掘出这些关联规则之后,我们可以基于这些规则给用户进行推荐。
- 基于模型的推荐(Model-based Recommendation)。这是一个典型的机器学习的问题,可以将已有的用户喜好信息作为训练样本,训练出一个预测用户喜好的模型,这样以后用户在进入系统,可以基于此模型计算推荐。这种方法的问题在于如何将用户实时或者近期的喜好信息反馈给训练好的模型,从而提高推荐的准确度。
协同过滤
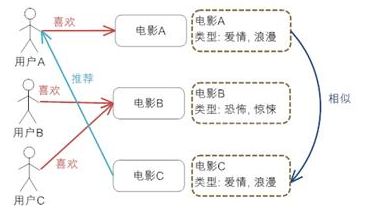
关于协同过滤的一个最经典的例子就是看电影,有时候不知道哪一部电影是我们喜欢的或者评分比较高的,那么通常的做法就是问问周围的朋友,看看最近有什么好的电影推荐。在问的时候,都习惯于问跟自己口味差不多的朋友,这就是协同过滤的核心思想。
步骤
要实现协同过滤,一般需要这样三步:
- 收集用户偏好
- 找到相似物或人
- 计算并推荐
收集用户偏好
从用户的行为和偏好中发现规律,并基于此进行推荐,所以如何收集用户的偏好信息成为系统推荐效果最基础的决定因素。用户有很多种方式向系统提供自己的偏好信息,比如:评分,投票,转发,保存书签,购买,点击流,页面停留时间等等。
当然,得到原始数据之后,我们总是需要进行降噪、归一化等,在此不再赘述。
找到相似物或人
既然是找相似,我们就需要设定一个计算相似度的指标,一般而言,余弦相似度与皮尔逊相关系数是很好的选择。
余弦相似度
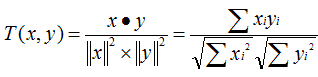
皮尔逊相关系数
皮尔逊相关也称为积差相关(或积矩相关)是英国统计学家皮尔逊于20世纪提出的一种计算直线相关的方法。
假设有两个变量X、Y,那么两变量间的皮尔逊相关系数可通过以下公式计算:

计算并推荐
- 基于用户的协同过滤推荐
基于用户的协同过滤推荐的基本原理是,根据所有用户对物品或者信息的偏好,发现与当前用户口味和偏好相似的“邻居”用户群,在一般的应用中是采用计算“K- 邻居”的算法;然后,基于这 K 个邻居的历史偏好信息,为当前用户进行推荐。
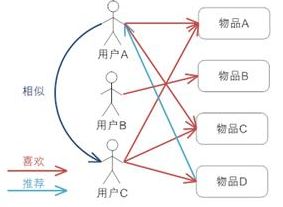
上图示意出基于用户的协同过滤推荐机制的基本原理,假设用户 A 喜欢物品 A,物品 C,用户 B 喜欢物品 B,用户 C 喜欢物品 A ,物品 C 和物品 D;从这些用户的历史喜好信息中,我们可以发现用户 A 和用户 C 的口味和偏好是比较类似的,同时用户 C 还喜欢物品 D,那么我们可以推断用户 A 可能也喜欢物品 D,因此可以将物品 D 推荐给用户 A。
基于用户的协同过滤推荐机制和基于人口统计学的推荐机制都是计算用户的相似度,并基于“邻居”用户群计算推荐,但它们所不同的是如何计算用户的相似度,基于人口统计学的机制只考虑用户本身的特征,而基于用户的协同过滤机制可是在用户的历史偏好的数据上计算用户的相似度,它的基本假设是,喜欢类似物品的用户可能有相同或者相似的口味和偏好。
- 基于项目的协同过滤推荐
基于项目的协同过滤推荐的基本原理也是类似的,只是说它使用所有用户对物品或者信息的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户。
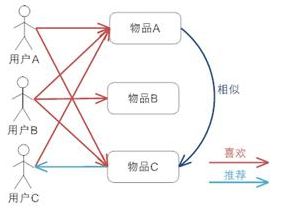
假设用户 A 喜欢物品 A 和物品 C,用户 B 喜欢物品 A,物品 B 和物品 C,用户 C 喜欢物品 A,从这些用户的历史喜好可以分析出物品 A 和物品 C 时比较类似的,喜欢物品 A 的人都喜欢物品 C,基于这个数据可以推断用户 C 很有可能也喜欢物品 C,所以系统会将物品 C 推荐给用户 C。
与上面讲的类似,基于项目的协同过滤推荐和基于内容的推荐其实都是基于物品相似度预测推荐,只是相似度计算的方法不一样,前者是从用户历史的偏好推断,而后者是基于物品本身的属性特征信息。
- 基于模型的协同过滤推荐
基于模型的协同过滤推荐就是基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测,计算推荐。
基于协同过滤的推荐机制是现今应用最为广泛的推荐机制,它有以下几个显著的优点:
它不需要对物品或者用户进行严格的建模,而且不要求物品的描述是机器可理解的,所以这种方法也是领域无关的。
这种方法计算出来的推荐是开放的,可以共用他人的经验,很好的支持用户发现潜在的兴趣偏好
而它也存在以下几个问题:
方法的核心是基于历史数据,所以对新物品和新用户都有“冷启动”的问题。
推荐的效果依赖于用户历史偏好数据的多少和准确性。
在大部分的实现中,用户历史偏好是用稀疏矩阵进行存储的,而稀疏矩阵上的计算有些明显的问题,包括可能少部分人的错误偏好会对推荐的准确度有很大的影响等等。
对于一些特殊品味的用户不能给予很好的推荐。
由于以历史数据为基础,抓取和建模用户的偏好后,很难修改或者根据用户的使用演变,从而导致这个方法不够灵活。
代码实现
基于用户的CF:
1 |
import java.util.HashMap; |
基于项目的CF:
1 |
import random |
The link of this page is https://blog.nooa.tech/articles/6f93935a/ . Welcome to reproduce it!