Simple Deterministic Algorithms for Fully Dynamic Maximal Matching
解决的问题
这篇文章介绍了什么是“完全动态最大匹配”,然后介绍了他们提供的在最坏情况下更新时间为平摊O(√m)(m表示图中的边数)时间复杂度、O(n+m)空间复杂度内完成的“3/2-近似最大基数匹配(MCM)”算法。这篇文章是为了处理图论中的“匹配”问题,作者将“图”分成[1]一般图,[2]低荫度[4]图 两种来处理。而对于每种图,处理步骤与方法基本一致,每种图都有——“插入”、“删除”两种操作,所不同的就是每种图所对应的情况(Case)不同而已。
采用的思想
这篇算法总体采用了分治的思想在每个小的情况下又有贪心算法的影子,本来“3/2-近似最大基数匹配(MCM)”这个问题相当难解决,而且已知算法中,要么时间复杂度为O(n),要么为O((n+m)√2/2)而且相当复杂,情况相当多。这篇算法一个很大的优点就是,思路清晰,作者将自己设计算法的思路,无遗地展现在读者面前。说起思路清晰,也就是分的情况条例清晰,也就是我们所说的分治思想。本来一个大问题不好求解,但我们可以通过将其分解为等价的几个小问题分别求解。
就像这篇算法,将“完全动态最大匹配”分为一般图与低荫度图两个部分来分别阐述,让算法在一般情况以及特殊情况都能游刃有余。
在应对每一大类图的各种操作(插入或删除)时,由于仍旧很复杂,所以作者又一次运用分治思想,将他们每个具体的操作继续分解为更小的几种情况,同时做到面面俱到,条理清晰。
在每一个小的情况下,遍历所有情况,找出能使匹配最大的情况,属于贪心的范畴,对于贪心算法,由于每种情况实在所要找的节点较少,所以我也认为贪心是比较不错的选择,而且,我们没必要在这样的小点上过于纠结。
基本算法描述
一般图
定义V={1,2……n}表示图的顶点的集合
为了简单处理,假定√n为整数;
定义G = (G0,G1……)表示图的集合,而且定义G0为空图,Gi由Gi-1得到;
对于每一个时间跨度i,Gi=(V,Ei),mi=|Ei| (m表示图中的边数)。
数据结构
M 存储在AVL树中(支持O(logn)时间复杂度的插入、删除)每个节点v处保存mate(v)返回当前匹配中的邻接顶点;
N(v) 存储在AVL树中(v∈V)用于存储节点v的邻接顶点,变量deg(v)存储v的度(无向图)(支持O(logn)时间复杂度的插入、删除以及取出r邻接顶点在O®时间复杂度内);
F(v)(v∈V)用于保存v的自由邻接节点(支持O(1)时间复杂度下的插入、删除以及如果有自由邻接顶点就返回TRUE的has-free(v)操作,O(√n)时间复杂度下的返回任意自由邻接顶点的get-free(v)操作),为了很好的得出F(v),还另外加了一个长度为n的Boolean型数组来表明当前自由邻接顶点、一个长度为√n的范围在[√nj+1,√n(j+1)]的计数数组来保存位置j处的自由邻接顶点的数目、一个变量来存储总的自由邻接节点数。
一个最大堆Fmax存储所有的以自身的度为权的自由节点(支持O(logn)时间内的插入、删除、update-key、find-max操作)。
具体算法
初始化图后,定义三个不变量,每次程序循环运行结束都不会突破这些不变量:
-
不变量1:所有节点度不超过√(2m+2n);
-
不变量2:在第i次循环变为自由节点的节点度不超过√(2m);
-
不变量3:M是最大匹配,而且没有长度为3的增光路径。
然后进行循环,每次循环对边ei进行操作。
插入边ei={u,v}的操作
首先更新相关的数据结构:N(u),N(v),deg(u),deg(v),Fmax以及u、v的值。
然后分如下四种情况讨论:
- u、v都已匹配,此时无需操作;
- u、v都是自由节点,这种情况下涉及更新M与Fmax,将u、v从F(x)中移除,花费O(√n+m)时间;
- u是自由的而v已被匹配,这种境况下,找到最大匹配集M中与v匹配的节点x=mate(v),再找到与x邻接的自由顶点w,如果能找到,则将匹配(x,v)移除,而将(u,v)、(x,w)加入。操作时间也在O(√n+m)内;
- v是自由的而v已被匹配,这种情况与上一种相对称。
删除边ei={u,v}的操作
删除操作主要分为两种情况:
- ei ∉ M 唯一要做的事就是,将u从F(v),v从F(u)中删去;
- ei∈M 由分为两种情况讨论:
- deg(u)≤√(2m) 时,我们必须通过aug-path(u)来所搜一条以u为起点的长度为3的增广路径,如果没有找到,那么直接标定v为自由节点即可,如果找到,定义u的自由邻接节点为w,w的邻接顶点为y,y的自由临界顶点为x,将{u,w}和{y,x}添加到匹配中而将{w,y}删除,同样的方法处理v。
- deg(u)>√(2m) 时,此时u不能自由,因为它的度太高。保持u匹配,我们通过surrogate(u)来获取u的代替节点,我们称呼为su,改变它的状态为自由,然后像在a)中处理u一样处理su。
对于低荫度图
在这部分中,考虑的是荫度不大于c的图,而c由下式确定:
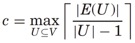
其中E(U)表示U中的边数。
由于图较稀疏,所以将每条边都带上方向,构成△-方向无向图
数据结构
与一般图基本相同。
具体算法
主要从:定向、插入、删除,几个部分来阐述:
定向
在每一步中,都通过运行算法A,来保证当前图是△-方向的。像如下算法中那样更新F和D,如果有t条边在定向,我们需要O(t)时间。
插入边ei={u,v}的操作
由于出度最多为△,所以插入时间O(△)。
删除边ei={u,v}的操作
未匹配的边被删除没什么可以操作的,但是当匹配的边被删除就有趣了,这里必须找到u(v)的匹配节点,时间复杂度仍为O(△)。
算法分析的结论
分析这个算法,其时间复杂度确实是平摊条件[4]下O(√m)(m表示图的边数);
其空间复杂度为O(m+n)。
这个算法确实能在最短的时间内的出“3/2-近似最大基数匹配(MCM)”。
用一个例子说明相关算法
为了较好的说明这个算法,我仅就自己画的一个图做些简要的分析,有遗漏之处实属算法没理解透:
(图如下,分别由6个顶点、7条边组成,由于算法本身要求图中点、边数目较多,而简短的语言无法描述清楚,所以选择这样一个简单的图来叙述)
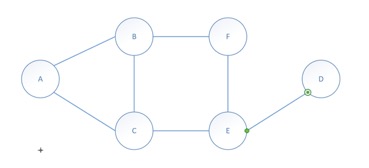
以下模拟算法过程:(只举例说明)
由文章知,该算法要处理动态图的最大匹配问题,首先初始化G0为空,我们按e0—e6的顺序向图中添加边,然后删除边。
- 将e0(AB)加入,直接将此边加入最大匹配M;
- 将e1(AC)加入,不操作;
- 将e2(BC)加入,不操作;
- 将e3(CE)加入,直接将此边加入M;
- 将e4(BF)加入,不操作;
- 将e5(EF)加入,不操作;
- 将e6加入,将此边加入M,同时将e3从M中删除,将e4加入,将e0删除,将e1加入M。
得到如下的最大匹配:
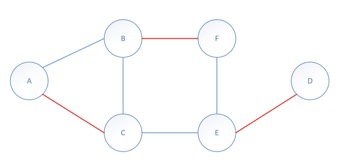
删除边时:
(由于删边不容易看出来,所以仅将出现可见变化时的情况列出。)
- 删除e0,不操作;
- 删除e1,将e1从最大匹配M中删除;
- 删除e4,将e2加入M,将e4删除。
得到的匹配如下:
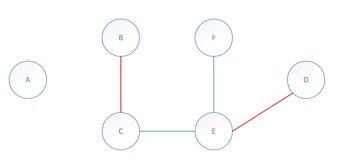
通过以上两个实例(一个删除、一个插入),基本能模拟本文关于动态最大匹配的一般算法。
认识与看法
已有算法的问题所在
-
算法提到对于低荫度图,给每条边改成有向边处理,然后用贪心算法求解,但是算法并未给出如何判断一个图是否是低荫度图,而且即使有了一个标准,那么当一个图先是低荫度图,后来因为添加一条边之后,成了算法判断的非低荫度图,之后再添加边……如此一来,后面添加边的匹配操作,仍然会按低荫度图处理,这样一来时间复杂度就明显升高了。与此相反,当一个图先是普通图,当减去一条边后,成了低荫度图,再继续减去边……后来虽然形成了低荫度图,但是仍然按普通图来处理的。——我的意思是,当加边/减边(一个更新操作)在普通图与低荫度图之间轮换时,算法会因每次都错开最好情况而用的时间急剧升高。在实际应用中,这种情况应该会很常见,所以我认为这个问题还是相当严峻的。
-
算法一直在说向图G,但这是一个“抽象”的概念,文中并没有提及这个图是怎么存储的,也没有提及添加/删除边是怎么进行的。我觉得这虽然是不起眼的一部分,但是它实现的好坏,却是后来算法的高效进行与否的保证。(在第四次作业中我将详细分析不同存储结构存储的图的不同之处,以及哪种存储对此算法的实现最有益。)
已有算法可改进之处
- 算法中提到对点的度按降序排列,但如果两个点的度完全一样,或者所有点的度完全一样时,这样的处理难免有些草率,和普通匹配算法没有这一处理操作的算法过程相似,甚至多了偶尔的不必要交换(当度相同时的交换),于是我想到,能不能通过增加一个标志位来改进交换同时由于考虑到一般情况下,顶点的度有大部分是相同的,所以可以考虑改进一下排序操作,找一个比较稳定的排序是比较好的。
- 算法用AVL树来存储匹配,这一点感觉是比较好的操作,但是当存储每个点的邻接点时,不仅又用AVL树来存储,而且需要用另外一个变量存储该顶点的度,而且每次插入/删除边(一个更新操作)都可能需要调整AVL树,于是,我想能不能用更好的适用于随机搜索(插入、删除)的数据结构,例如:散列表来存储邻接顶点呢?这样一来,搜索的时间由O(logN)减小到O(1),空间基本不会增加,反而减少一个整型空间(每个顶点减少一个,共N个),插入/删除边的时间大约也是O(1),这样一来就比以前的算法要改进了一些(具体实现,见作业四)。
- 算法中提到用一个数据结构F(v)来存储顶点v的邻接顶点中未匹配的顶点,及其信息。然后算法提到一个长度为n(n表示所有顶点数量)的数组以及一个长度√n的计数数组。这种处理,在原则上是没有什么错误的,但是长度为n或者√n的数组没法实现每次插入顶点时就没法用了,为了实现完全动态匹配,我们需要用一个更好的数据结构来完成这一操作(当然对于本算法,这一改进并没有什么作用,但是想到可以为算法进行拓展,所以这个改进是必要的),我想到的数据结构是动态表——一种最省空间,且扩充/缩减时间O(1)(由摊还分析可证)的数据结构。
- 当数据量较大,短时间有较多条边需要插入/删除时,(通过插入操作来说明)每次操作,都是先将边加入存储边的数据结构,然后再依次更新其他相邻节点的邻接信息,以及边的信息。最后再分情况(动态规划)依次判断以及做出调整,简单来讲,整个判断过程分为三个部分,而且这三个部分是相互独立的,所以假如有N次插入,那么就有3N步,正常情况(该算法原来描述那样)。在一次插入边的操作结束后,存储边的数据结构便空闲下来,而第二次边的插入还没有开始。中间这部分时间浪费严重(当大数据来临时)。
已有算法不适用之处
- 算法一开始是通过一个空的数据结构开始插入边,来建立匹配,假如已有一个大数据的图(数据在外存,一般来说数据量过大,没法一次性装入内存)或者,由于数据量过大,没法普通存储(或者为了省空间、减小出错率)而用压缩图来存储,如果仍然用现有的算法来做,是极其困难的。也许可以实现,但是也困难重重,我仅将其归为不适用的一类。
改进意见
- 针对第一处问题。为了在每一步都使算法做到最优,那么在低荫度图与普通图的转换接口处,就应该更加重视,为了解决这个问题,我觉得,可以在每增加/删除一条边(一个更新操作)时增加一次判断,即:max[|E(U)|/(|U|-1)]>C时,就进行普通图的操作,否则进行低荫度图的操作,其中C为预设的荫度的分界线。同时,首先对普通图的操作,或者对低荫度图的操作,当第一次出现两种图混合时,再初始化另一种图的存储结构,这样一来如果一直是基于两者中一种图的更新操作,就不需要那么大的空间开销。
在原算法,没有这一判断时,相对现在的改进,在每一次更新操作的时间上先是少一步,但当更新操作在多次往往复复地在两种图之间转换时,虽然改进多了一次判断,但是避免了两种图用同一种算法实现的时间消耗,算法改进的正确性及合理性得证。
- 针对第二处问题。我觉得这里的问题是作者的一个疏忽,当然在这个算法中,选用哪种数据结构来存储图,确实不是那么好选择的。选用邻接矩阵时,虽然边的信息清晰明了,但是,当数据量增大时,空间开销也是挺大的。若选用邻接表,减少了空间开销,但是,当每次统计某个节点的邻接顶点时,显得有些麻烦,邻接多重表,十字链表等弊端就更多与优点了。于是,在此改进中,我仅仅提出“邻接矩阵”与“邻接表”这两种存储图的数据结构来存储这个算法有关的图,这样,相对来说,比其他数据结构要简单,以及开销较小(时间/空间上)。
这两种图的存储结构,都可以实现边的插入/删除在O(1)时间内,并且相对其他存储结构还比较好实现,于是正确性得证。
- 针对第一处不足。我觉得可以增加一个标志位(整型)来实现对同一个度的不同节点做一下区分,第一次度为某个值的顶点标记为1,以后如果再有和这个点度相同的标记为2,……以此类推,每次为了保证度越高的节点越先匹配,不仅要判断度的大小,同时当度相等时,还要判断标志位,标志位越小(越大也行)就越优先保持匹配。
这一改进,使该算法对多顶点度相等的图,效果明显,当然当顶点度基本都不相同时,这一改进显得一无是处,反而增加空间开销。但就对程序改进角度讲,这样做着实可以在某些情况下,增加算法正确性,减少算法时间复杂性,我觉得这可以作为改进合理性的证明。
- 针对第二处不足。我觉得可以用散列表来存储每个顶点的邻接点信息,这样一来,可以减少一个整型变量空间,同时使搜索某个点是否与另一个点邻接能够在O(1)时间内完成(这也是散列表的最大的用处)。当然,散列表的构造也有很多方式,这里可以假设之前每个顶点都有一个ID或者有一个单独的可区分的标识。当以顺序ID来标记每个顶点时,可以用直接寻址法;当以单独的可区分标识来标记每个顶点时,可以用数据分析法来确定散列函数。
该改进的正确性,可以通过散列表在搜索上的正确性来证明,同时在空间复杂性上可能比以前算法要多(当然也可能相同),但在搜索时间上,对原有算法改进是十分显著的。由此,改进的合理性由此得证。
- 针对第三处不足。这一点属于“个人爱好”,为什么这么说呢?因为这一改进对原有算法不会产生一丁点的影响,但是却为程序可拓展性做了一点贡献。用动态表代替原有长度固定的数组,当顶点个数增多时,可以避免每次不够用又重新手动申请空间的弊端。可以说,动态表这一数据结构完美适应了顶点可变的情况,当边减少时,那些独立的顶点,可以通过某种方式,将其删去,以减少空间复杂性,同时,顶点减少,搜索更快;当边增多时,如果某些顶点原来没有记录,再在动态表中将其加入,丝毫不用担心空间分配麻烦问题。
动态表实现简单,效率高,事实上它和普通数组相比基本没有效率损失。我觉得即使是原算法思想(即使没边,也有顶点)也可以用动态表代替数组。
- 针对第四处不足。当大数据来临时,我将每次的匹配过程看成三部分,这让我想起了《计算机组成原理》中关于指令流水线的介绍,我发现该算法中三部分之间互相无关联,于是,我就想能不能仿照指令流水线的方式,来改进已有算法的三段匹配过程呢?也就是说,当第一条边插入时,我顺序开始执行那三段操作,当执行完第二段时,第二次插入已经可以开始执行了……依次类推,当大量数据进行同一个操作(插入/删除边)时,就可以成倍地减少时间复杂性(将三段融合成一段)。
这一改进符合并行性要求,而且可以证明,原来程序的三段互不影响,那么这个改进就显得在大数据上大有用武之处。
- 针对第一处不适。由于该算法是每次(动态)加入边,而现实是需要先初始化一个图,而且还可能是大量的数据的图,所以该算法不适用之处就显现出来了。虽然如果将已经存在的大数据图里的边一个个挑出来再加入,可以完成此操作,但是考虑时间将会是特别大的。于是想到,能不能给该算法在加一点能够对静态图匹配的内容,以便其能够在大数据上发挥作用。
如今,数据已进入海量时代,应对大数据冲击,已经成为考验所有算法好坏的一个标准,于是对此算法往大数据上适应,是十分有必要的。
The link of this page is https://blog.nooa.tech/articles/8e9f2014/ . Welcome to reproduce it!