Attention
Seq2Seq结构在一些End2End问题上能取得非常好的结果,其结构一般由Encoder和Decoder组成,其运行流程如下视频所示。
然而,采用RNN的Seq2Seq结构因为RNN中存在长程梯度消失的问题,很难将较长输入的序列转化为定长的向量而保存所有的有效信息。所以随着句子的长度的增加,这种结构的效果会显著下降。为了解决这一由长序列到定长向量转化而造成的信息损失的瓶颈,Attention机制被引入了。Attention机制跟人类翻译文章时候的思路有些类似,即将注意力关注于我们翻译部分对应的上下文。此机制打破了只能利用Encoder最终单一向量结果的限制,从而使模型可以集中在所有对于下一个目标单词重要的输入信息上,使模型效果得到极大的改善。还有一个优点是,我们通过观察Attention权重矩阵的变化,可以更好地知道哪部分翻译对应哪部分源文字,有助于更好的理解模型工作机制。
Attention机制实际上是对Query, Key, Value 的运算,其整体流程可以用下图来表示。
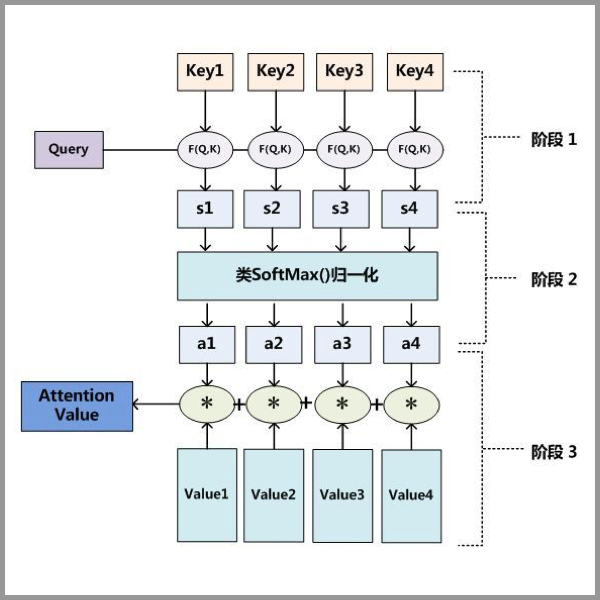
其中:
- 阶段一是
Query与Key进行某种F()运算; - 阶段二是使用
softmax对结果归一化; - 阶段三是上阶段输出值和
Value做运算。
F()运算可以是:$$Q^{T}K$$, $$Q^{T}W_{a}K$$ 或者 $$v_{a}^{T} tanh(W_{a} concat(Q, K))$$。
Self Attention
如果Attention机制中的Key, Value以及Query都来着同一个分布,我们称之为Self-Attention。
接下来,结合网上的一个例子,我们从数据输入、计算Key, Value和Query、再到具体的三阶段计算来认识Self-Attention。
数据准备
我们准备了三个输入,每个输入维度为4。如下:
1 |
Input 1: [1, 0, 1, 0] |
计算Key,Value以及Query
假设我们希望Key, Value, Query的尺寸为3。而由于现在每个输入的尺寸均为4,这意味着每组权重的形状都必须为4×3。
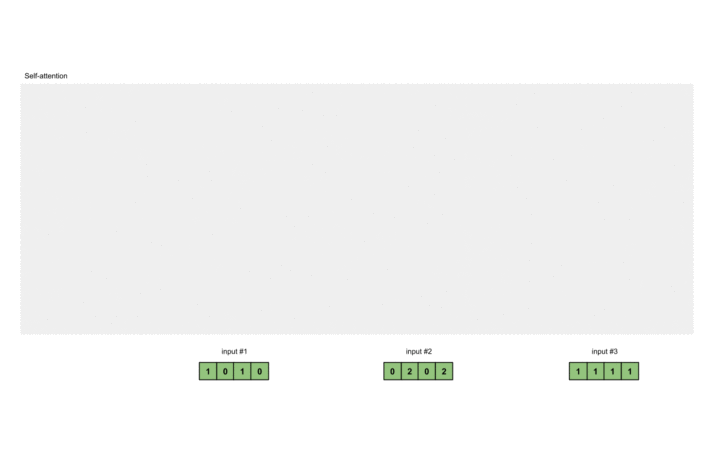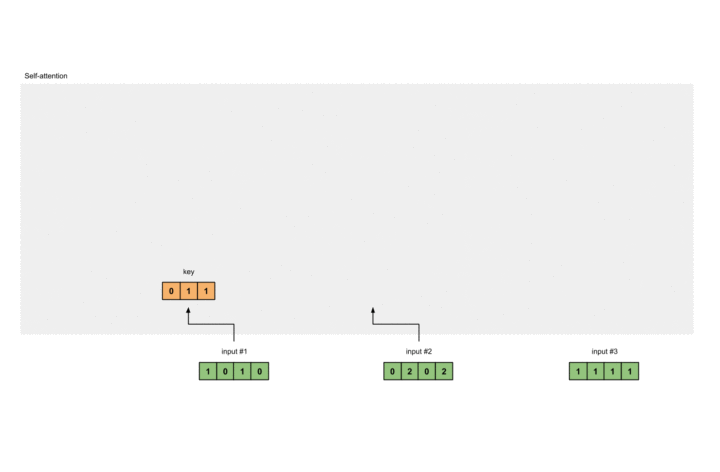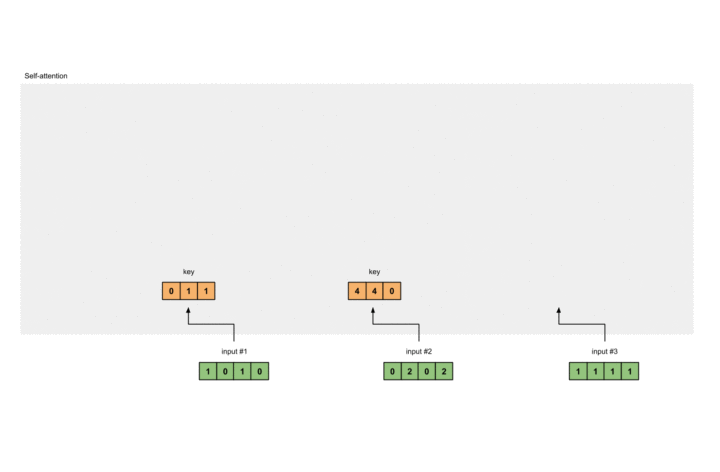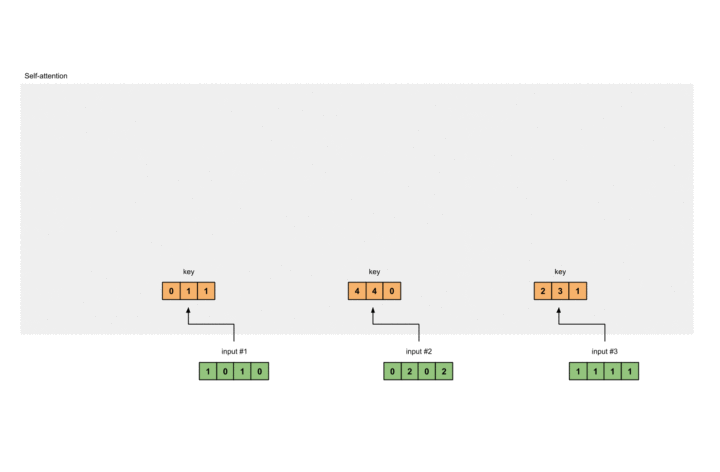
计算Key
我们假定Key的权重为:
1 |
[[0, 0, 1], |
则通过矩阵乘法,我们可以得到Key为:
1 |
[0, 0, 1] |
此过程如下图所示:
计算Value
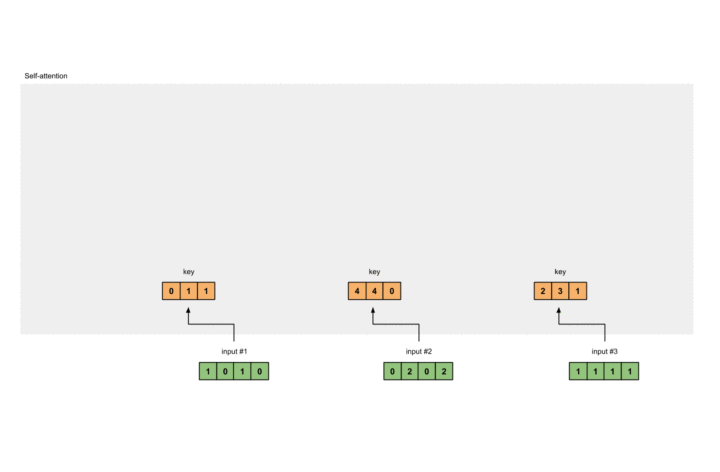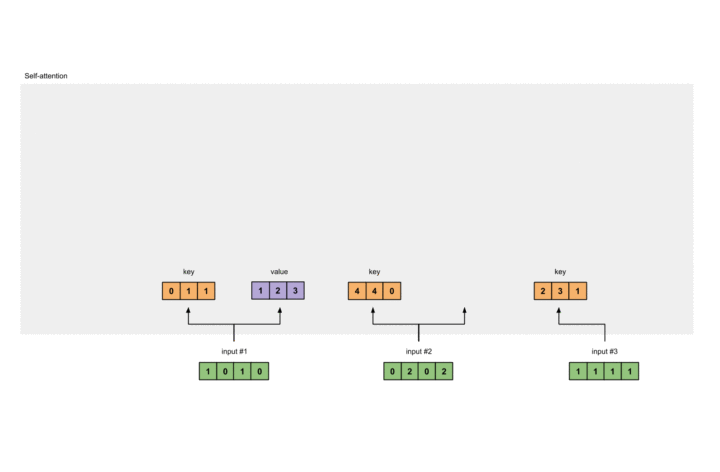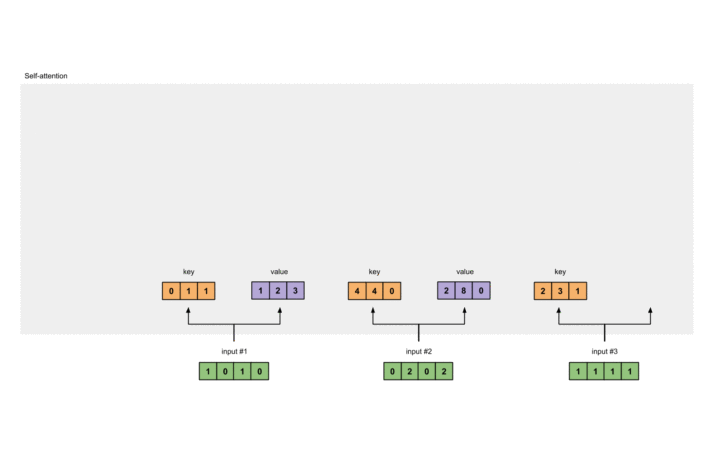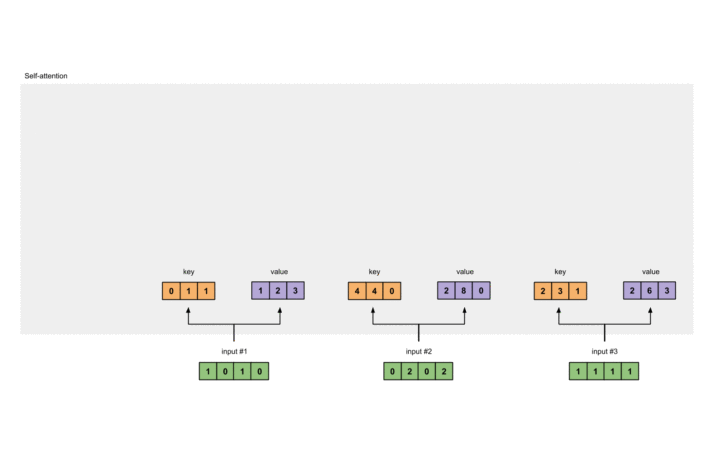
同理,Value权重及计算如下:
1 |
[0, 2, 0] |
此过程也有图片展示:
计算Query
同样的方式可以计算Query:
1 |
[1, 0, 1] |
动图表示此过程如下:
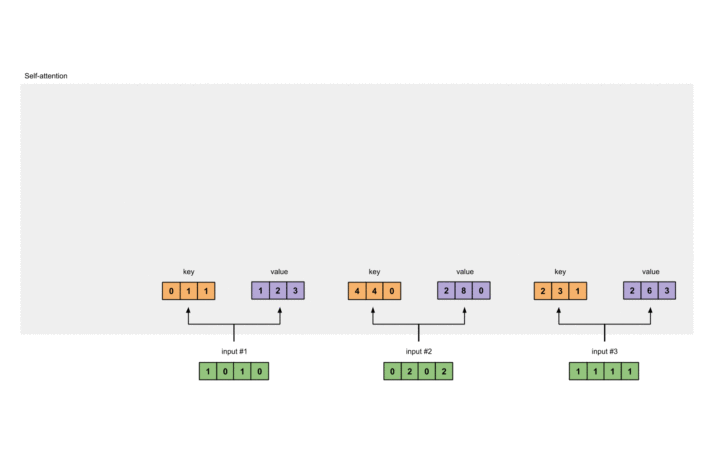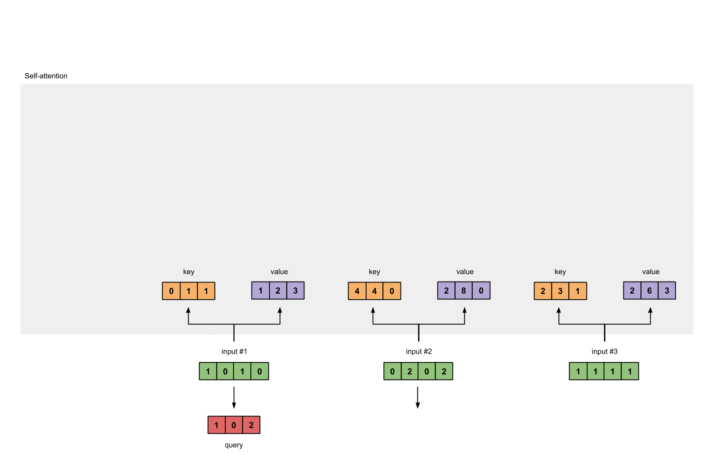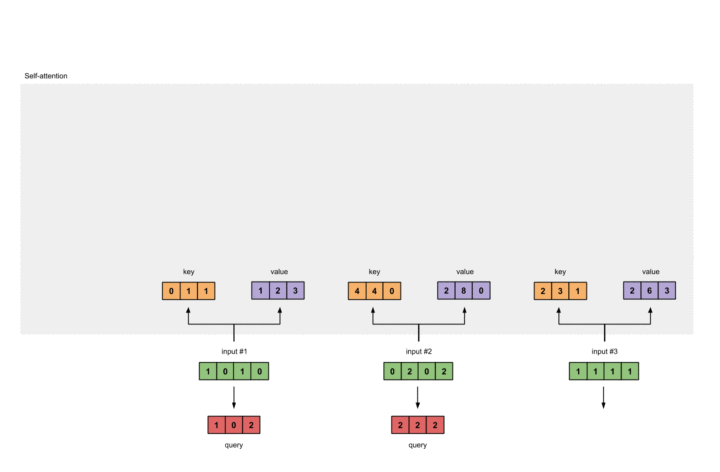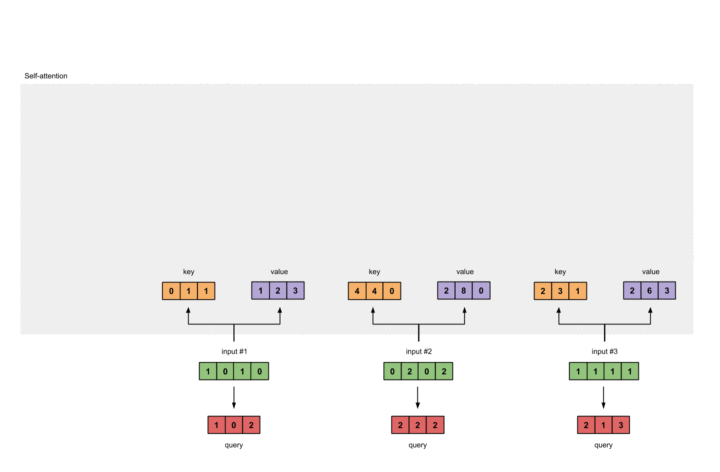
至此,我们可以得到来自同一分布的Key, Value以及Query。
三阶段计算
F()运算
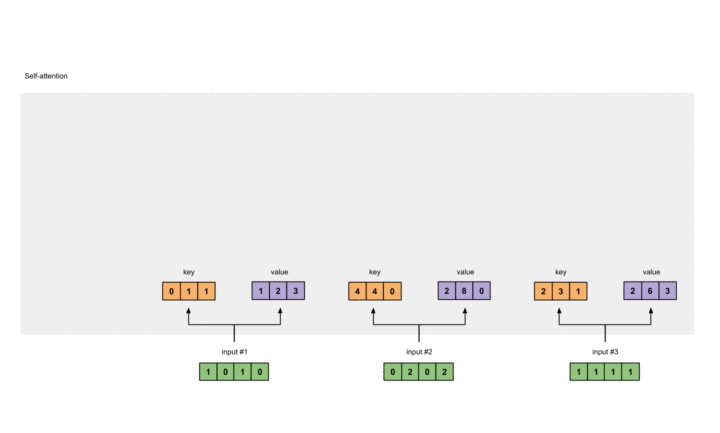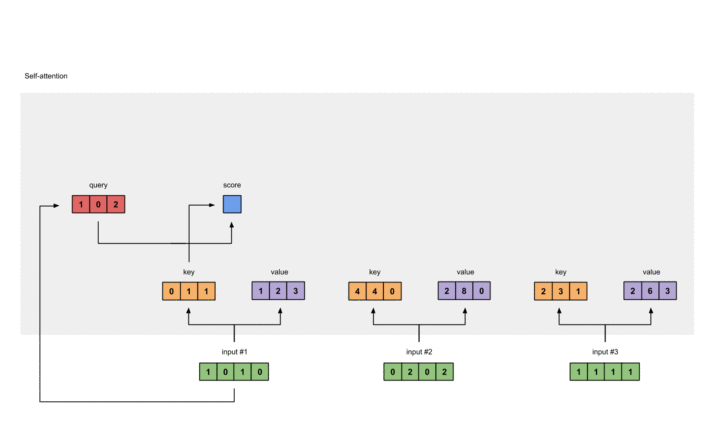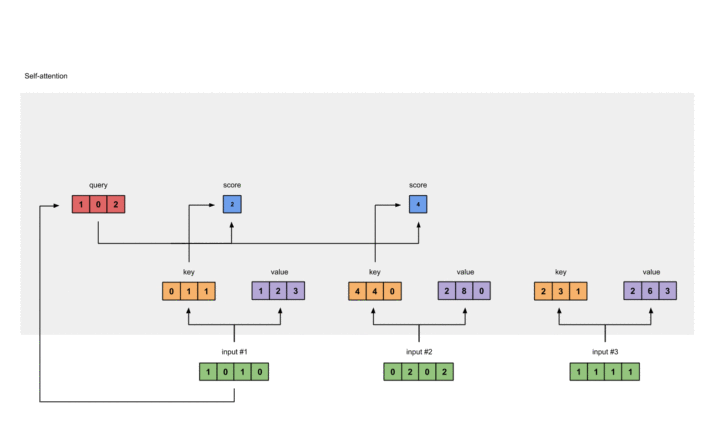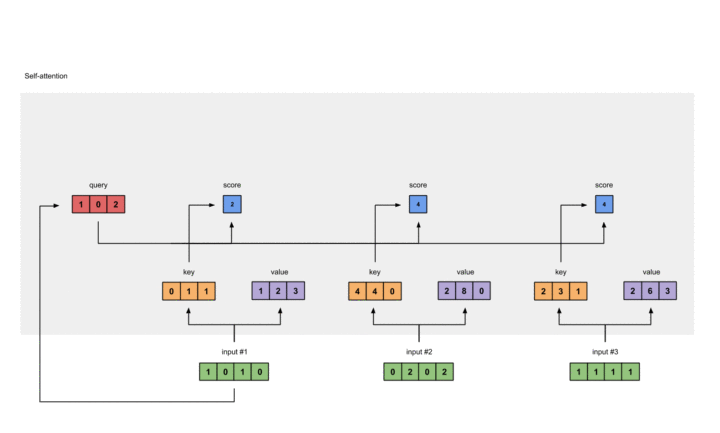
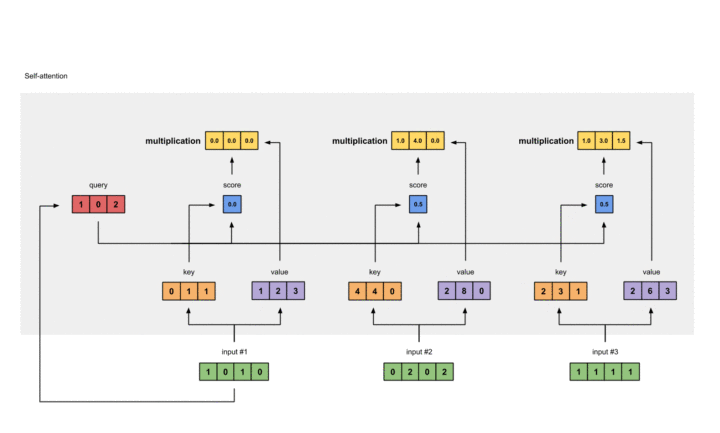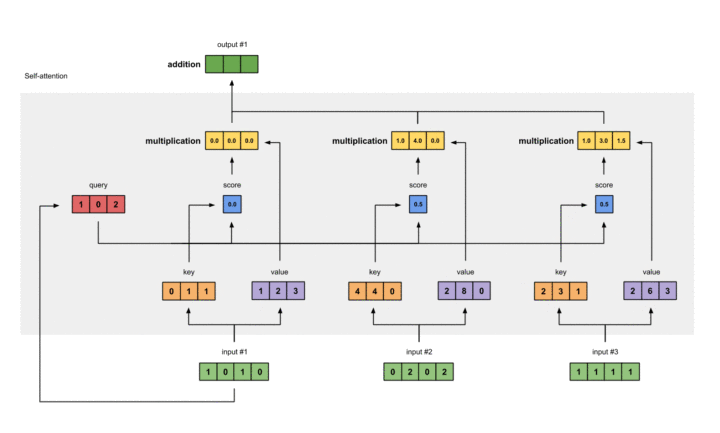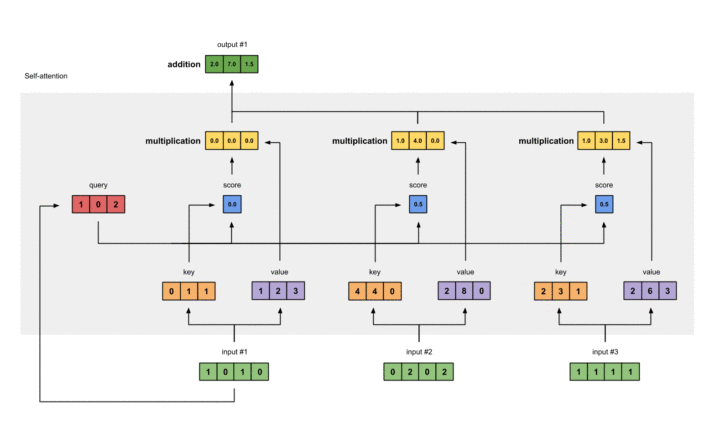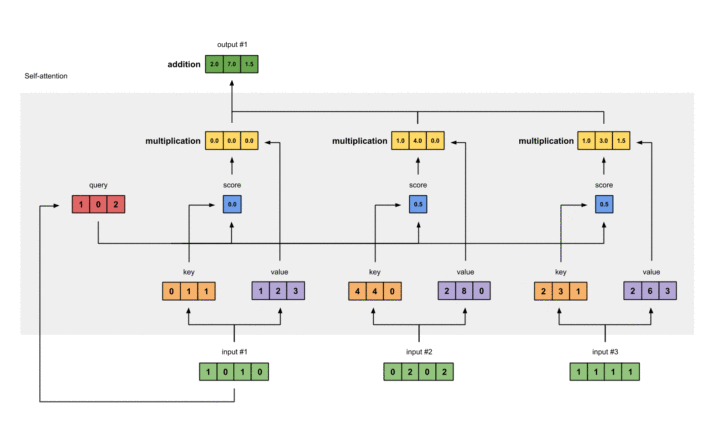
在此,我们选择点乘作为我们的F()。对于第一个Query,我们可以得到其注意力得分:
1 |
[0, 4, 2] |
过程如下:
softmax归一化
以上视频展示了softmax的过程,softmax本身是这样一个公式:
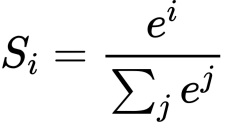
得到Attention Value
针对某一个Query,其经过以上两步之后的输出与Value分别想乘并结果想加,可以得到对应位置的Attention Value,在本实例中得到第一个值的过程大致如下:
分别得到三个Query对应的三个Attention Value的过程如下:
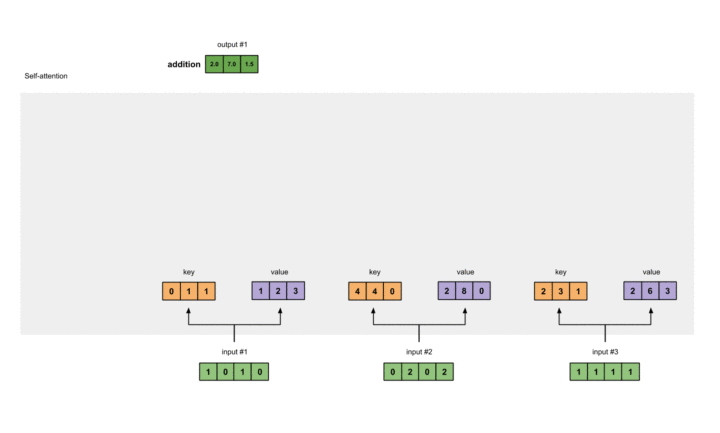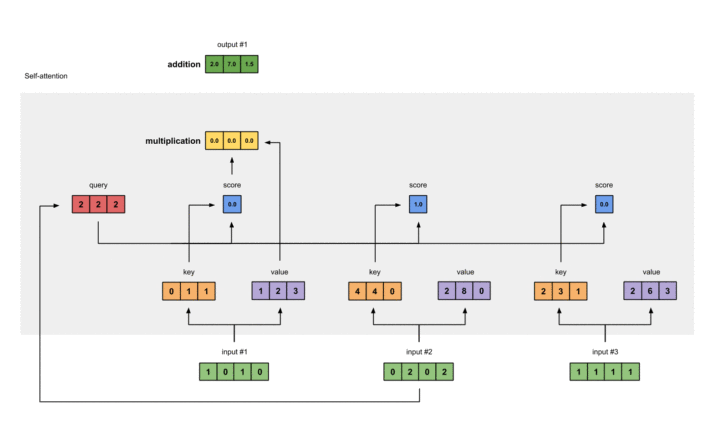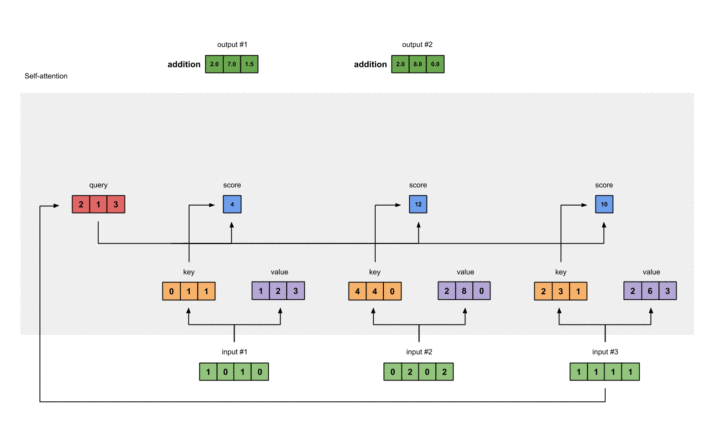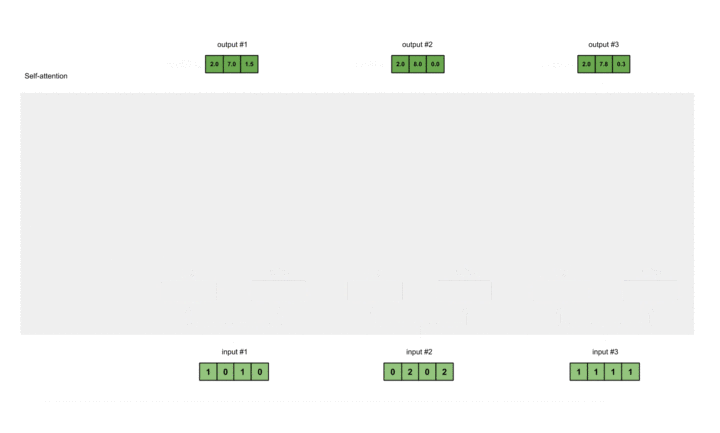
至此,Self-Attention的全流程以及实例完毕。
Applications
Attention机制引入以来,主要用在以下三个场景中。
Sequence to sequence
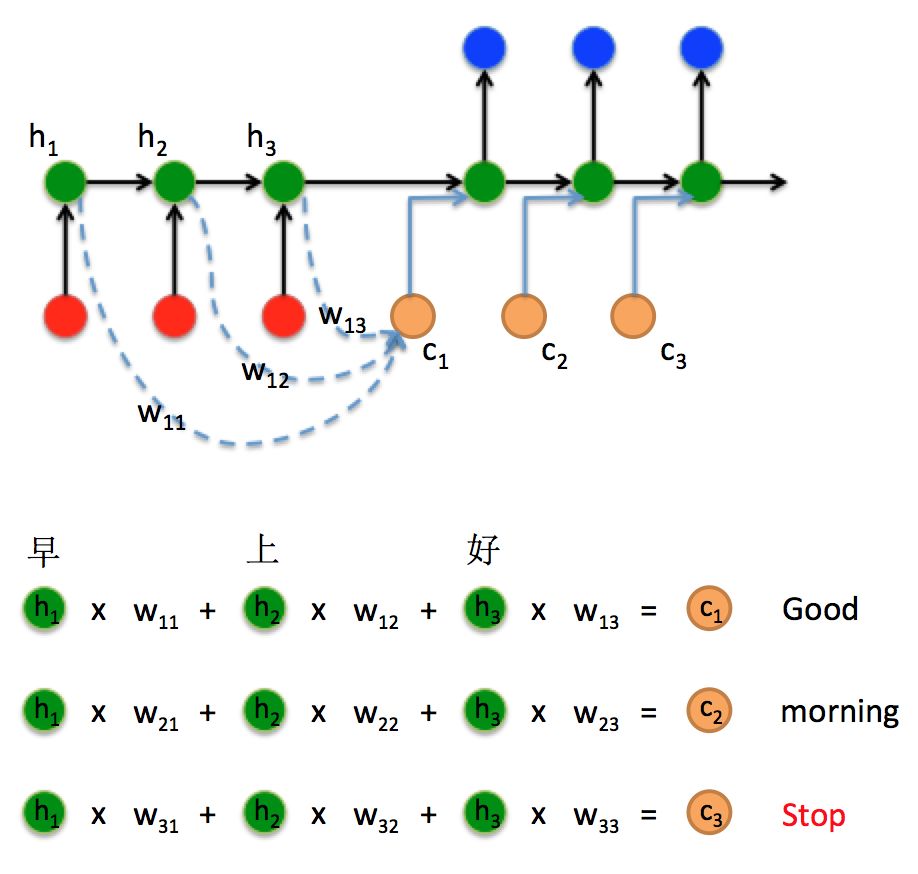
引入了Attention的Seq2Seq结构如上图,Encoder不再是只保存最终的状态,而是保存整个Attention Value矩阵,在Decoder时,可以更好的得到所需要的结果。
Transformer
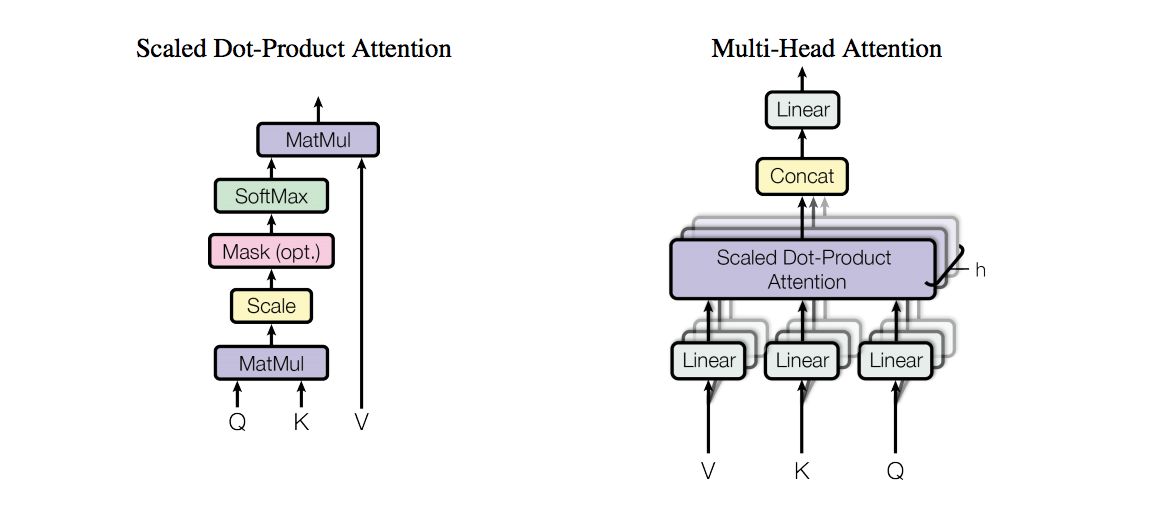
Transformer是另一个使用到Attention的模型,更具体的说是Multi-head Attention。其结构图如下所示:
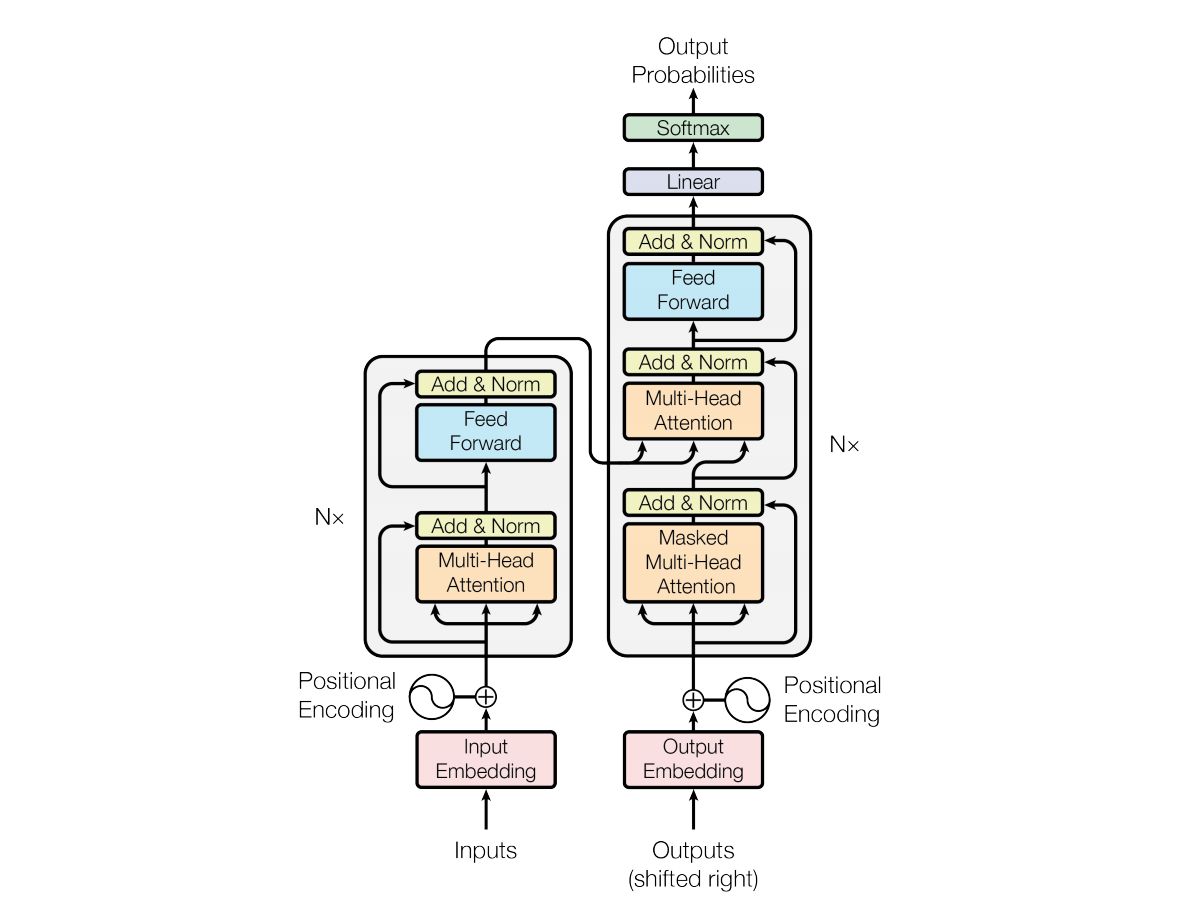
其中,Multi-head Attention是通过h个不同的线性变换对Query,Key以及Value进行投影,最后将不同的Attention结果拼接起来。其与加了mask的Attention原理如下图。
BERT
BERT的网络架构是完全重用Transformer的Encoder部分,一个创新亮点就是训练中使用的目标函数,也就是Loss function的定义。这个创新虽小但是很关键。BERT的Loss function由两个子任务的Loss相加而得。第一个任务就是把一个句中的几个字mask掉,然后让模型去预测这几个字,看它的正确率。第二个Loss来源于预测两个句子是不是上下句。这是为了让模型拥有句子层面的语义相关性的判断。为了增加鲁棒性,这两个句子都有可能不是整句,而是片段。
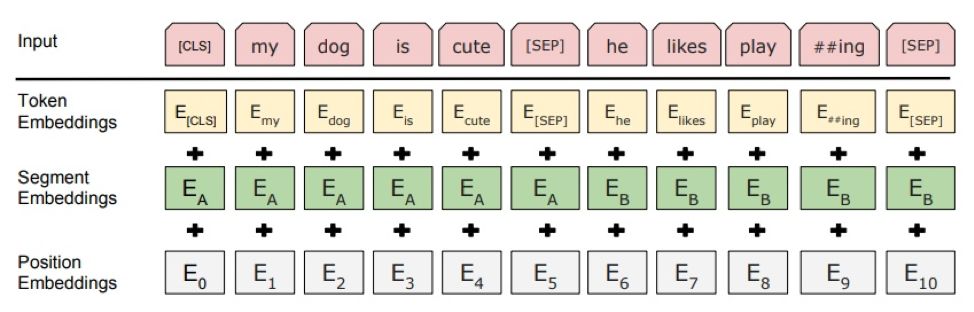
除此之外,BERT的Input Embedding也是一大亮点,其考虑到Attention并没有考虑的位置信息,增加了Segment Embeddings和Position Embeddings,他们和Token Embeddings的和作为Input Embeddings。
The link of this page is https://blog.nooa.tech/articles/9d18641a/ . Welcome to reproduce it!