自己开发一个搜索引擎,可能是每一个计算机爱好者的梦想,但是当我们看到网上开源搜索引擎那么庞大时,未免有点害怕。那么开发一个搜索引擎真的很难么?
本博文在阅读了《How to Develop a Search Engineer》之后,总结而成。
代码下载:Wiser
搜索引擎简介
搜索引擎(Search Engine)是指根据一定的策略、运用计算机技术从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务。在日常生活中,可以看到 Google 等 Web 检索网站,还有邮件检索和专利检索等各种应用程序。
背景知识
在自己写一个搜索引擎之前,需要先了解基本的原理和概念。比如分词,倒排索引,排序算法(BM25、PageRank)等。
搜索引擎工作步骤分为这几步:
- 爬虫模块 Crawler 在网页上抓取感兴趣的网页数据存储为 Cached pages
- 索引构造器 Indexer 对 Cached pages 处理生成倒排索引(Inverted Index)
- 对查询词 Query 在倒排索引中查找对应的文档 Document
- 计算 Query 和 Document 的关联度,返回给用户 TopK 个结果
- 根据用户点击 TopK 的行为去修正用户查询的 Query,形成反馈闭环。
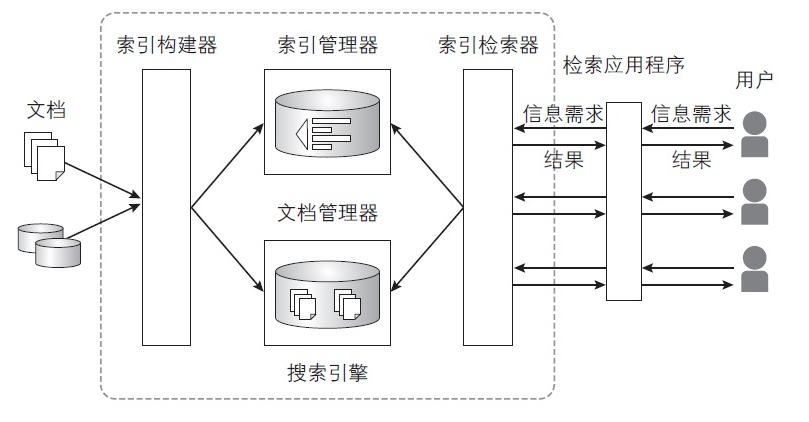
搜索引擎的四大组件:
- 文档管理器(Document Manager)
- 索引构建器(Indexer)
- 索引管理器(Index Manager)
- 索引检索器(Index Searcher)
组件关系图:
Wiser使用
编译运行
下载好wiser.zip文件,并解压缩到相应位置,进入文件夹,运行make wiser,稍待片刻,即可完成编译。
收集数据
在本次使用wiser的实验中,直接从https://dumps.wikimedia.org/zhwiki/latest/下载相应的xml文件即可(省去了实际的爬虫过程)。
使用wiser存入sqlite使用命令:wiser -x XXX.xml -m 100 wiki.db
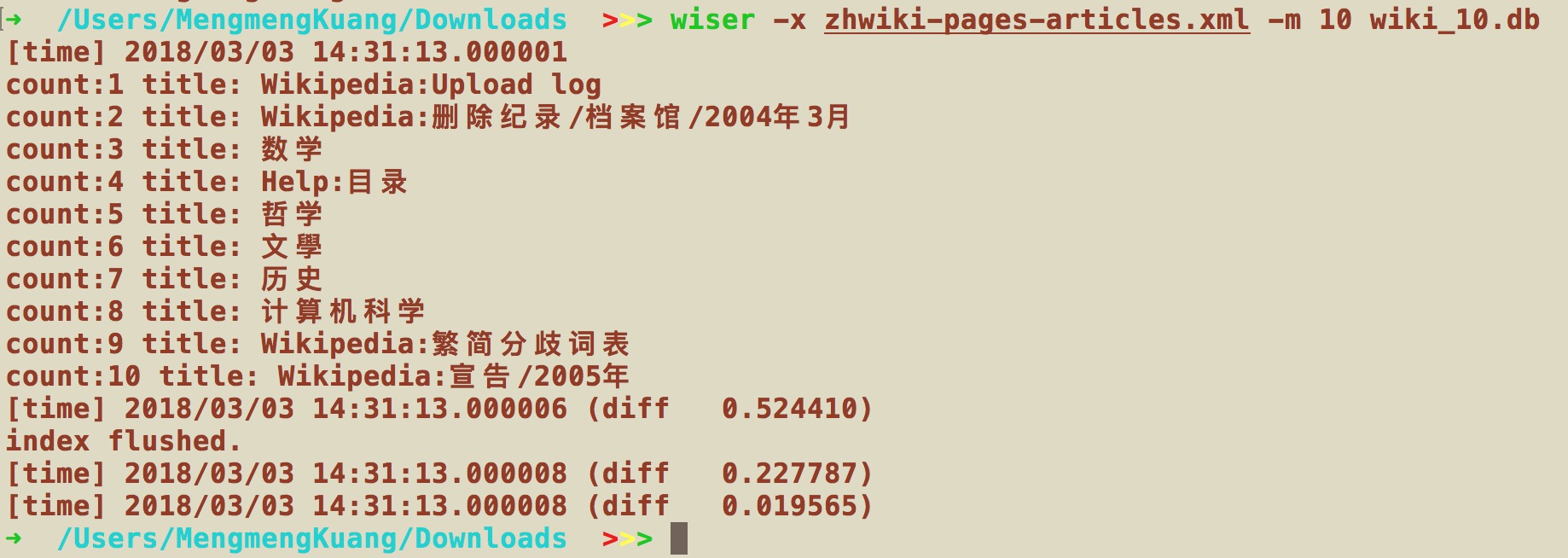
此时,我们已经将10条数据存入.db文件中了。
构建倒排索引
*在上一步已经完成。
检索文档
使用wiser搜索一个关键词使用命令:wiser -q "XXX" wiki.db
排序并呈现

从截图中可见,score代表匹配指数,已经计算好,并返回给我们。
Wiser代码剖析
在此先简单的介绍各个主要的.c文件实现的功能:
wiser.c: 主程序,接收命令行输入,并相应的调用其他函数;database.c: 操作sqlite,包括增,查等功能;search.c: 全文检索,TF-IDF求相关度;postings.c: 倒排索引压缩与解压缩;token.c: 创建倒排索引,N-gram分词;wikiload.c: 加载wikipedia上下载的xml文件;util.c: 编码相关的杂项。
其他详情,还请实际使用啊!
The link of this page is https://blog.nooa.tech/articles/c49b2caf/ . Welcome to reproduce it!