I/O体系结构
虚拟文件系统利用底层函数,调用每个设备的操作,那么这些操作是如何在设备上执行的,操作系统又是如何知道设备的操作是什么的呢?这些是由操作系统决定的。
我们知道,操作系统的工作,是依赖于数据通路的,它们让信息得以在CPU、RAM、I/O设备之间传递。这些数据通路称为总线。这就包括数据总线(PCI、ISA、EISA、SCSI等)、地址总线、控制总线。I/O总线,指的就是用于CPU和I/O设备之间通信的数据总线。I/O体系的通用结构如图所示:
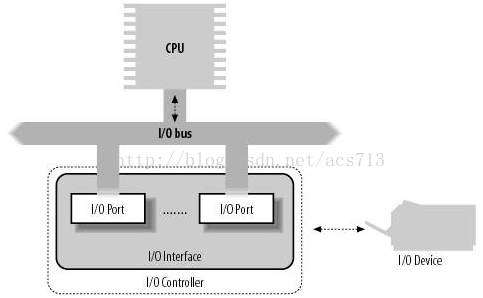
那么CPU是如何通过I/O总线和I/O设备交互呢?这首先得从内存和外设的编址方式说起。第一种是“独立编址”,也就是内存和外设分开编址,I/O端口有独立的地址空间,这也被称为I/O映射方式。每个连接到I/O总线上的设备,都分配了自己的I/O地址集(在I/O地址空间中),它被称为I/O端口。in、out等指令用语CPU对I/O端口进行读写。在执行其中一条指令时,CPU使用地址总线选择所请求的I/O端口,使用数据总线在CPU寄存器和端口之间传送数据。这种方式编码逻辑清晰,速度快,但空间有限。
第二种是“统一编址”,也被称为内存映射方式,I/O端口还可以被映射到内存地址空间(这也正是现代硬件设备倾向于使用的方式),这样CPU就可以通过对内存操作的指令,来访问I/O设备,并且和DMA结合起来。这种方式更加统一,易于使用。它实际上使用了ioremap()。自从PCI总线出现后,不论采用I/O映射还是内存映射方式,都需要将I/O端口映射到内存地址空间。
每个I/O设备的I/O端口都是一组寄存器:控制寄存器、状态寄存器、输入寄存器和输出寄存器。内核会纪录分配给每个硬件设备的I/O端口。
设备驱动程序模型
在内核中,设备不仅仅需要完成相应的操作,还要对其电源管理、资源分配、生命周期等等行为进行统一的管理。因此,内核建立了一个统一的设备模型,提取设备操作的共同属性,进行抽象,并且为添加设备、安装驱动提供统一的接口。它们本身并不代表具体的对象,只是用来维持对象间的层次关系。
这里首先要提的是sysfs文件系统。和/proc类似,安装于/sys目录,其目的是表现出设备驱动程序模型间的层次关系。在驱动程序模型当中,有三种重要的数据结构(旧版本),自上到下分别是subsystem、kset、kobject。如果要理解这个模型中,每个数据结构的作用,就必须理解它们和操作系统中的什么东西相对应。它们均对应着**/sys中的目录**。kobject是这个对象模型中,所有对象的基类。kset本身首先是一个kobject,而它又承担着一个kobject容器的作用,它把kobject组织成有序的目录;subsys则是更高的一层抽象,它本身首先是一个kset。驱动、总线、设备都能够用设备驱动程序模型中的对象表示。
设备驱动程序模型中的组件
设备驱动程序模型建立在几个基本数据结构之上,它们描述了总线、设备、设备驱动器等等。这里,我们来看看它们的数据结构。首先,device用来描述设备驱动程序模型中的设备。
1 |
struct device { |
首先,可以看到device中包含有一个kobject,还包含有它相关驱动对象。所有的device对象,全部收集在devices_kset中,它对应着/sys/devices中。设备的引用计数则是由kobject来完成的。device还会被嵌入到一个更大的描述符中,例如pci_dev,它除了包含dev之外,还有PCI所特有的一些数据结构。device_add完成了新的device的添加工作。我注意到,error = bus_add_device(dev); ,也就是说device的添加会把它和bus关联起来。
再来看看驱动程序的结构。其数据结构为device_driver。相对于设备的数据结构来说,它相对较为简单:对于每个设备驱动,都有几个通用的方法,分别用语处理热插拔、即插即用、电源管理、探查设备等。同样,驱动也会被嵌入到一个更大的描述符中,例如pci_driver。
1 |
struct device_driver { |
为什么这里没有kobject呢?它实际上保存在了driver_private当中,这个结构和device_driver是双向链接的。
1 |
struct driver_private { |
driver的添加,通过调用driver_register()来完成,它同样包含一个函数:bus_add_driver(),也就是将driver添加到某个bus。
再来看看总线的结构。bus是连接device和driver的桥梁,bus中的很多代码,都是为了让device找到driver来设计的。总线的数据结构如下:
1 |
struct bus_type { |
同样,总线也有一个subsys_private,它保存了kobject。but_type中定义了一系列的方法。例如,当内核检查一个给定的设备是否可以由给定的驱动程序处理时,就会执行match方法。可以用bus_for_each_drv()和bus_for_each_dev()函数分别循环扫描drivers和device两个链表中的所有元素,来进行match。
设备文件
设备驱动程序使得硬件设备,能以特定方式,响应控制设备的编程接口(一组规范的VFS函数,open,read,lseek,ioctl等),这些函数都是由驱动程序来具体实现的。在设备文件上发出的系统调用,都会由内核转化为对应的设备驱动程序函数,因此设备驱动必须被注册,也即构造一个device_driver,并且加入到设备驱动程序模型中。在注册时,内核会试图进行一次match。注意,这个注册的过程基本driver_register通常不会在驱动中直接调用,但我们但驱动通常都会间接的调用它来完成注册。
遵循linux“一切皆文件”的原则,I/O设备同样可以当作设备文件来处理,它和磁盘上的普通文件的交互方式一样,例如都可以通过write()系统调用写入数据。设备文件可以通过mknod()节点来创建,它们保存在/dev/目录下。
linux当中,硬件设备可以花费为两种:字符设备和块设备。其中,块设备指的是可以随机访问的设备,例如硬盘、软盘等;而字符设备则指的是声卡、键盘这样的设备。设备文件同样在VFS当中,但它的索引节点没有指向磁盘数据的指针,相反地它对应一个标识符(包含一个主设备号和一个次设备号)。VFS会在设备文件打开时,改变一个设备文件的缺省文件操作,让它去调用和设备相关的操作。
字符设备驱动程序
这里我们以字符设备驱动程序为例。首先,字符设备的驱动,在linux系统中,是以cdev结构来表示的:
1 |
struct cdev { |
现在让我们回顾一下inode的数据结构:
1 |
struct inode { |
我们看到了cdev指针的影子,可见cdev和inode确实是直接相关的。要实现驱动,首先就要对cdev进行初始化,注册字符设备。驱动的安装,首先要分配cdev结构体、申请设备号并初始化cdev。注意,驱动程序是如何和刚才我们所说的设备驱动模型建立联系的呢?实际上在初始化cdev的时候,就调用了kobject_init(),在模型中添加了一个kobject。
随后,驱动要注册cdev,也即调用cdev_add()函数。这个工作主要是由kobj_map()来实现的,它是一个数组。对于每一类设备,都有一个全局变量,例如字符设备的cdev_map,块设备的bdev_map。最后要进行硬件资源的初始化。
1 |
int cdev_add(struct cdev *p, dev_t dev, unsigned count) |
kobj_map的结构如下,它用来保存设备号和kobject的对应关系
1 |
struct kobj_map { |
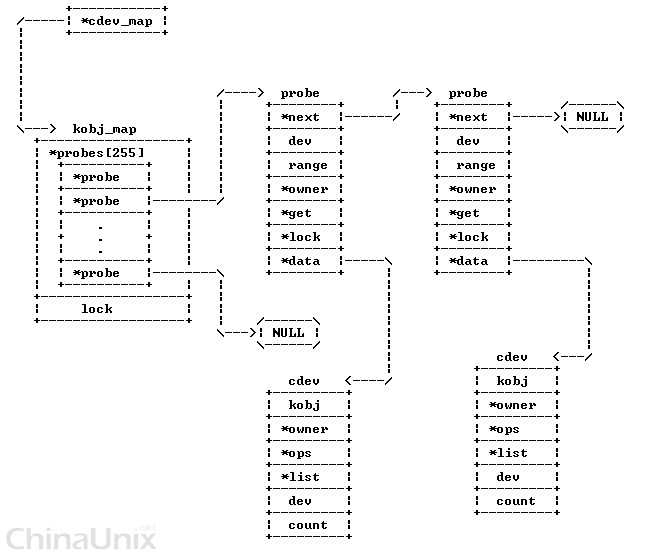
不过到现在为止,我们都还没有说明,程序在访问字符设备时,是如何去调用正确的方法的。我们曾提到过,open()系统调用会改变字符文件对象的f_op字段,将默认文件操作替换为驱动的操作。在字符设备文件创建时,会调用init_special_inode来进行索引节点对象的初始化。其inode的操作(def_chr_fops)只包含一个默认的文件打开操作,也即chrdev_open。它会根据inode,首先利用cdev_map,找到对应的kobject,随后再进一步找到cdev,然后从中提取出文件操作的函数fops,并把它填充到file当中去。
1 |
static int chrdev_open(struct inode *inode, struct file *filp) |
这里很奇怪的是,我们并没有看到类似前面提到的driver_register()、device_register()这样的函数。实际上这里并没有真正创建一个设备,而只是说创建了一个接口,所以有这样一个这个问题:为什么cdev_add没有产生设备节点?对于这个问题,我们应该理解为cdev和driver/device二者是配套工作的,cdev用来和用户交互,而device则是内核中的结构。
另一个问题是,在上面的过程中,似乎没有提及设备文件的创建。实际上,作为一个rookie,那么设备文件常常是用mknod命令手动创建的。当然,linux自然也提供了自动创建的借口,那就是利用udev来实现,调用device_create()函数。
当然,这个例子只是为了说明,操作系统的驱动程序是如何工作的,为什么对I/O设备的操作可以抽象成对设备文件的操作,程序在操作I/O文件时,是如何使用正确的操作的。
块设备的驱动
和字符设备类似,操作系统中的块设备,也是以文件的形式来访问。这里有一个很拗口的问题:磁盘是一个块设备,块设备有一个块设备文件。那么访问块设备文件和访问普通的磁盘上的文件有什么关系呢?
不论是块设备文件还是普通的文件,它们都是通过VFS来统一访问的。只不过对于一个普通文件,它可能已经在RAM中了(高速缓存机制),因此它的访问可能会直接在RAM中进行;但如果说要修改磁盘上的内容,或者文件内容不在RAM中,则也会间接地,通过块设备文件进行访问。这个驱动模型可以用这样一个图表示:

这里我们只考虑最底层的情况:内核从块设备读取数据。为了从块设备中读取数据,内核必须知道数据的物理位置,而这正是映射层的工作。映射层的工作包括两步:
- 根据文件所在文件系统的块,将文件拆分成块,然后内核能够确定请求数据所在的块号;
- 映射层调用文件系统具体的函数,找到数据在磁盘上的位置,也就是完成文件块号,到逻辑块号的映射关系。
随后的工作在通用块层进行,内核在这一层,启动I/O操作。通常一个I/O操作对应一组连续的块,我们把它称为bio,它用来搜集底层需要的信息。
I/O调度层负责根据内核中的各种策略,把待处理的I/O数据传送请求,进行归类。它的作用是把物理介质上相邻的数据请求,进行合并,一并处理。
最后一层也就是通过块设备的驱动来完成了,它向I/O接口发送适当的命令,从而进行实际的数据传送。
通用块层
通用块层负责处理所有块设备的请求,其核心数据结构就是bio。它代表一次块设备I/O请求。
1 |
struct bio { |
在这个数据结构中,还包含了一个bio_vec。这是什么意思呢?在linux中,相邻数据块被称为一个段,每个bio_vec对应一个内存页中的段。在io操作期间,bio是会一直更新的,其中的bi_iter用来在数组中遍历,按每个段来执行下一步的操作。
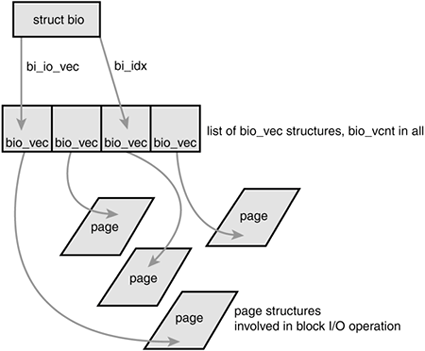
那么当通用块层收到一个I/O请求操作时,会发生什么呢?首先内核会为这次操作分配bio描述符,并对它进行填充。随后通用块层会调用generic_make_request,这个函数的作用很明确:它会进行一系列检查和设置,保证bio中的信息是针对整个磁盘,而不是磁盘分区的;随后获取这个块设备相关的请求队列q,调用q->make_request_fn,把bio插入请求队列中去。
I/O调度层
在块设备上,每个I/O请求操作都是异步处理的,通用块层的请求会被加入块设备的请求队列中,每个块设备都会单独地进行I/O的调度,这样能够有效提高磁盘的性能。
前面提到,通用块层会调用一个q->make_request_fn,向I/O调度程序发送一个请求,该函数会进一步调用__make_request()。这个函数的目的,就是把bio放进请求队列当中:(1)如果请求队列是空的,就构造一个新的请求插入;(2)如果请求队列不是空的,但是bio不能合并(不能合并到某个请求的头和尾),也构造一个新的请求插入;(3)请求队列不是空的,并且bio可以合并,就合并到对应的请求中去。注意,bio,请求和请求队列的关系如下:
1 |
-- request_queue |
const struct file_operations def_blk_fops = {
.open = blkdev_open,
.release = blkdev_close,
.llseek = block_llseek,
.read = new_sync_read,
.write = new_sync_write,
.read_iter = blkdev_read_iter,
.write_iter = blkdev_write_iter,
.mmap = generic_file_mmap,
.fsync = blkdev_fsync,
.unlocked_ioctl = block_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = compat_blkdev_ioctl,
#endif
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
};
`dentry_open()`方法会调用`blkdev_open()`。它(1)首先会获取块设备的描述符:如果块设备已经打开,则可以通过inode->i_bdev直接获取,否则则需要根据设备号去查找块设备描述符。(2)获取块设备相关的`gendisk`地址,`get_gendisk`是通过设备号来找到gendisk的。(3)如果是第一次打开块设备,则要根据它是整盘还是分区,进行相应的设置和初始化。(4)如果不是第一次打开,只需要按需要执行自定义的`open()`函数就行了。
# 补充:I/O的监控方式
- 轮询:CPU重复检查设备的状态寄存器,直到寄存器的值表明I/O操作已经完成了。
- 中断:设备发出中断信号,告知I/O操作已经完成了,数据放在对应的端口,当数据缓冲满了时,由CPU去取,CPU需要控制数据传输的过程。
- DMA:由CPU的DMA电路来辅助数据的传输,CPU不需要参与内存和IO之间的传输过程,只需要通过DMA的中断来获取信息。DMA能够在所有数据处理完时才通知CPU处理。
<br><br>The link of this page is [https://blog.nooa.tech/articles/d0c0e94a/](https://blog.nooa.tech/articles/d0c0e94a/) . Welcome to reproduce it!